Introduction
For years, AMD is pushing the idea of treating CPU and GPU equally when comes to computing power through the concept called “heterogenous computing”. After all, why would you waste all of the power and space in a PC if certain workload can be better suited for the GPU as oppose to CPU. Even better would be to have both CPU and GPU working concurrently in parallel to finish a task faster. AMD started talking about such concept with the Fusion platform in 2006 which leads to the company’s acquisition of ATI.
While the concept of heterogenous computing sounded good, getting there is not an easy task. To achieve such goal, it requires a fundamental redesigning of the processor. A lot of work and engineering is needed not just in the hardware but also software. AMD started moving toward true heterogenous computing slowly with the Brazo platform that put the CPU and GPU on the same chip. Then with the Llano, AMD integrated the Northbridge to the same chip and created the Radeon Memory Bus. Trinity/Richland, AMD fine-tuned the architecture and brings us Turbo Core, and allows the GPU to address the system memory.

Essentially, all of the APUs that was released were more of a CPU with a GPU on the same chip than a true co-processors. Finally, with the release of Kaveri, AMD has gotten all of the interconnect between the CPU and the GPU worked out so that it can finally treat the CPU and GPU as equal partner and delivers the true “heterogenous computing” that it has set to achieve.
With Kaveri, AMD has further refined the Bulldozer microarchitecture that is now in its third generation. Codenamed Steamroller, the CPU on the Kaveri is able to deliver a better performance at lower power consumption. The GPU on Kaveri does get a major upgrade from the Cayman derived VLIW4 to GCN microarchitecture, the same that is found on the current generation of the AMD GPU. However, what is the most exciting about the Kaveri in our opinion is not the processors upgrade but rather the underlying interconnects between the CPU and the GPU that AMD has implemented with the heterogenous system architecture (HSA).
HSA, hQ, hUMA,
With HSA, AMD has finally found the last puzzle that is needed in order to achieve a true heterogenous computing where both the CPU and GPU are treated co-processors with coherent access to virtual memory and system level atomics for synchronizing workloads across the cores. HSA eliminates the need for data copying back and forth between the CPU and the GPU instead, both cores are able to access the same data in the same place on the memory. Kaveri brings us three new technologies hUMA, hQ, and HSAIL.
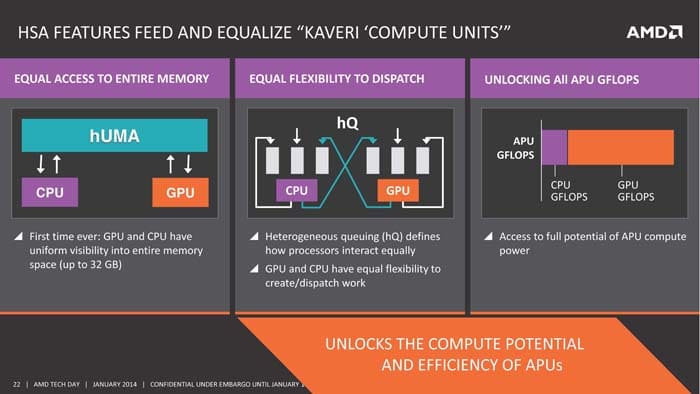

We have talked about hUMA in the past. The quick summary about hUMA is that it finally allows the system memory to be seen by both CPU and the GPU. Both cores are able to access the same memory so that no longer system needs to copy data back and forth between the two cores. hUMA implements pointer system where an entire data structure with all of the embedded links can be passed to GPU. Having both CPU and GPU share the same memory space not only removed the unnecessary overhead from copying data between the two cores, it also allows both cores to on the same data at the same time to even concurrently to finish work faster.

Besides hUMA, AMD also brings hQ to the HSA to further improves on the efficiency between the different processor cores. hQ brings user-mode queuing to reduce overhead of job dispatching between CPU and GPU. In addition, GPU can enqueue work for itself and even able to queue CPU call back function.
Now with hUMA and hQ, AMD essentially allows both CPU and GPU to behave like co-processors in the APU as oppose to have the GPU depended on the CPU. As the HSA is not only limited to just CPU and GPU, it is possible that other processors can be added to the mix where it can also share the same memory space so that work can be distributed to whoever is best suited for a given task. AMD has added ARM Cortex A5 to some of the APU for hardware security and it also has plan to build their own ARM chip. So it is possible in the future we will see ARM chip that is also HSA compatible where it will able to work in conjunction with CPU and the GPU as well as other special processor cores.
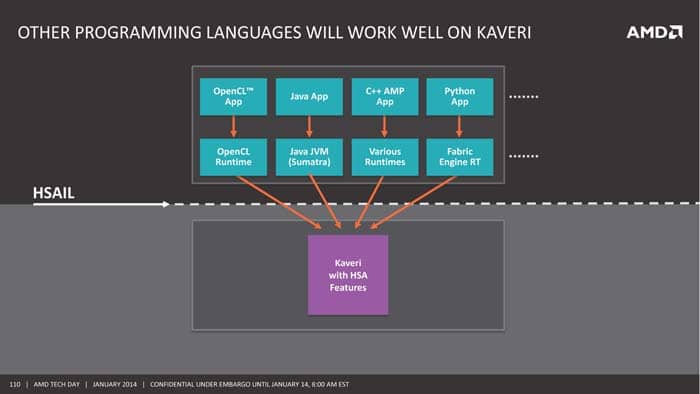
AMD has laid down the foundation and have the hardware ready with HSA and now it just need to get the developers onboard. Traditionally software development has always lagged behind the hardware development. And to get the software developers to create applications or optimized their current applications for HSA, AMD and other members of the HSA foundation has standardized HSAIL, an intermediate language that bridges the gap between the high-level language and the machine code. The idea here is to allow developers to continue to use their current high-level language like OpenCL or C++ and the LLVM compiler will generate HSAIL binary object format which the HSA Finalizer ingest then translate to the native machine code. HSAIL is not an API instead it is an intermediate language that creates runtime and map to the hardware of the vendor’s ISA.
As HSA is an open standard not AMD’s own proprietary, this intermediate translation language allows the same software to work across all different hardware GPU, CPU, ARM, DSP, etc. HSA foundation includes not just AMD but alsoother industry giants like Samsung, Qualcomm, ARM and others. While currently, AMD is the only active member at creating hardware and pushing the software development, it is very possible if AMD is able to succeed at getting developers onboard to create software to take advantage of HSA, we will see others to jumps onboard with other hardware designs. Furthermore, as mentioned, AMD’s future roadmap that includes both x86 and ARM SoCs, HSAIL would allow software to be used on either processor without the need to be rewritten.
Kaveri marked the world first OpenCL 2.0 ready chip. Though, the driver is not currently available to take its hardware advantage. AMD promised a driver to be released toward the end of the year. It will first be on Linux system.




With the new architecture, someone might get more perf gains from overclocking the memory and fsb before going after the multiplier.