
AMD today brings the latest implementation of the heterogeneous computing with the introduction of the heterogeneous queuing (hQ). As you may recall, AMD founded the Heterogeneous System Architecture (HSA) Foundation with other chipmakers and industry giants such as ARM, Qualcomm, and Samsung to promote a great utilization of various computing processors such as CPU, GPU, DSP and others . The goal of the HSA is to bring ISA agnostic to the chip and brings all of the computing resources to equal footing.
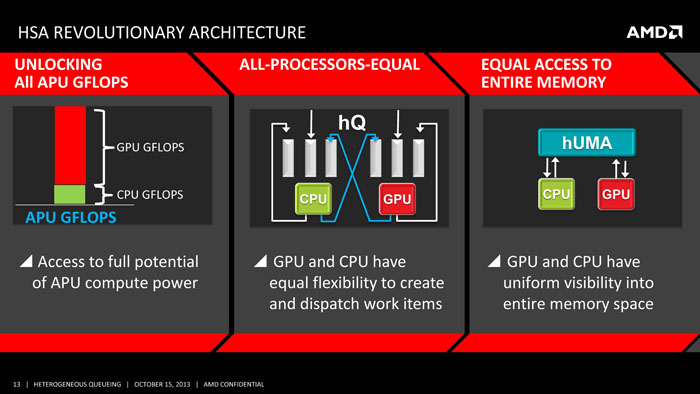
AMD’s drive toward HSA started with the integration of CPU and GPU into a single die (Llano). Later this year, AMD will release the Kaveri APU that features the heterogenous uniformed memory access (hUMA). Kaveri will bring fully coherent memory where CPU and GPU are able to access the memory with the same address space. Pointers can be passed between the two. This allows the GPU to use pageable system memory.
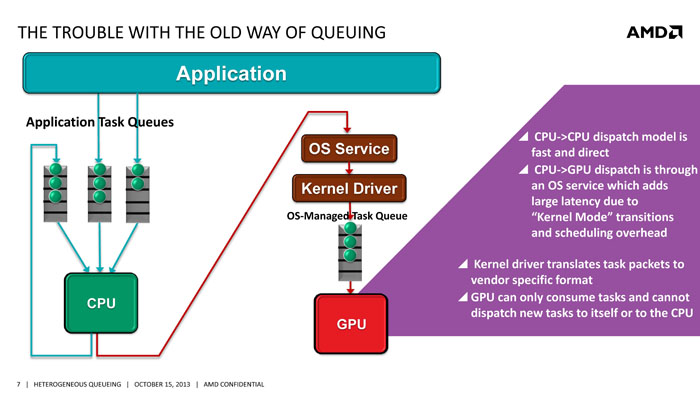
The next step in the HSA is the “heterogeneous queuing” or hQ. HSA devices communicate with one another using queues. Traditionally, CPU is the central task manager where a command from the software goes to the CPU and then it dispatch queue to other hardware and components like GPU in the PC. If a workload is designed for GPU, it must first go to CPU and then the CPU dispatches the work to the GPU through OS service or “kernel mode” transition. Then the kernel driver translates task packet to the vendor specific format.
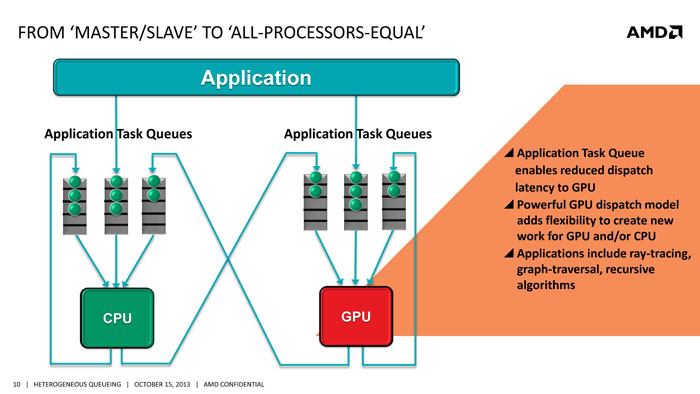
Such design adds overhead and latency so AMD is aimed to reduce the unnecessary steps with the heterogeneous queuing (hQ). With hQ, AMD brings user-mode queuing where application code is directly access to the hardware and dispatch to the appropriate processor. With the user mode queuing, CPU places GPU work item directly onto a task queue without the need to invoke OS or Kernel mode transition. This helps to reduce latency. The hQ allows both the GPU and CPU to create and dispatch work items. The queue allocation and destruction is managed with HSA runtime. Programmers have the option to manage the queue directly or use a library function to submit task dispatches. Depending on the complexity of the HAS hardware, queues might be managed by any combination of software or hardware.
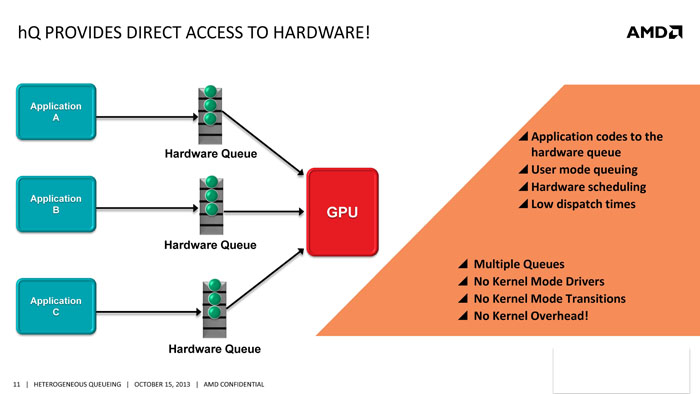
In addition, hQ allows the the GPU to enqueue itself and even create new work for CPU.
With hQ:
- CPU can queue to GPU: typical scenario of OpenCL
- GPU can queue to another GPU even itself:
- GPU can queu to an CPU: allows workload running on GPU to request system operation such as memory allocation or I/O
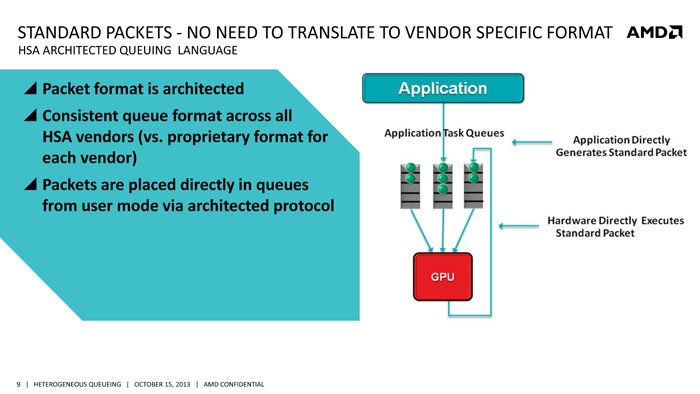
Since AMD HSA is an open standard. The HSA queuing language will be open to any software engineers. It employees standard packet format where the application directly generates standard packet that are placed in queues. The packet gets to send to the hardware directly where the hardware then execute it. The packet has pointer to instruction code, resource allocation in order to run the compute kernel. The oepn standard means that it will support by all HSA-compatible hardware and eliminate the need for vendor specific code. For AMD APU, the hardware scheduler moved to the GPU itself to eliminate the need for the kernel.

AMD’s current plan will support Winodws first with Linux in the works. Other OSes support will come later.





