We got to see Fermi (GF100) at a private meeting in Vegas this past week and Fermi is looking good beyond belief good. The feature set has been redefined.
Fermi
Lets preface this article by saying that we saw Fermi in action on several applications and can attest to the fact that the information contained in the Whitepaper is true and accurate. This isn’t a here’s the info we were handed and regurgitating it blindly.
Fermi is looking very powerful on the order of 100% performance gain, in some applications, and packed with revolutionary technology that could very well change the face of computing. By computing we mean GPGPU or parallel computing which is gaining a firm hold in the PC world. Now we know some of you are saying oh great a folding GPU that isn’t going to do crud for us in gaming. Wrong, Fermi games better than the best we’ve seen to date and we can easily say it is the most powerful single core GPU we have ever seen. However that’s not what this article is about. This article is about the newly redefined feature set Nvidia is putting on the plate with Fermi and general Fermi design as related to GTX-2xx.
This isn’t a core re-hash it’s a top down core redesign and from what we can see it addresses more shortcomings of GTX-2xx (don’t get us wrong we love our GTX-2xx lineup of cards) than we expected. Right out of the gate lets do a short but not complete list of features that Fermi got that GTX-2xx didn’t, DX11, Tessellation, Parallel polygon processing, shared L2 Cache, up to 32xCSAA (up from 16x), GDDR5, Nvidia Surround (triple monitor acting like one monitor) Nvidia 3D Vision Surround.
Every advantage that Nvidia was being held to task on (In comparison to ATI) that we can think of has been included in this redesign. That leads to another question, how well was it implemented. Even though the software and drivers used for the demos we saw were pretty rough we only saw one crash and that was on a somewhat Beta demo Nvidia is working on to include with Fermi. Every other application we saw ran flawlessly and we can say with a high degree of confidence when Fermi is finally released to the public (End of Q1 2010 at the latest) it will be a highly polished launch.

There are a few items being finalized on Fermi, the fan, packaging, software, drivers but the core is in it’s final state before launch. We may see core shrinks, variants to fill the price points, and more mature drivers but Fermi’s core is a done deal.
Fermi Whitepaper Report
We wish that we could give you this information in a more polished form but we had about 60 hours to do a workup after CES and received the slide decks. We lost about 24 of those hours on a password protected document problem that kept us from opening the PDF files we needed for the article. So we are settling for an almost verbatim reconstruction of the Nvidia GF100 Whitepaper. It’s in a good format and it’s Fermi as described by Nvidia. We doubt that we could give you more accurate or easy to understand info than Nvidia presents themselves. This is a reproduction so there are some minor differences. Mainly picture repositioning.

Dedicated to the World’s PC Gamers
Over the years, the continuing and insatiable demand for high quality 3D graphics has driven NVIDIA to create significant GPU architectural innovations. In 1999, the GeForce 256 enabled hardware transform and lighting. In 2001, GeForce 3 introduced programmable shading. Later, GeForce FX provided full 32-bit floating point precision throughout the GPU. And in 2006, GeForce 8 introduced a powerful and efficient unified, scalar shader design. Each GPU we designed was intended to take graphics closer to reality, and to distinguish the PC as the most dynamic and technologically advanced gaming platform.
NVIDIA’s latest GPU, codenamed GF100, is the first GPU based on the Fermi architecture. GF100 implements all DirectX 11 hardware features, including tessellation and DirectCompute, among others. GF100 brings forward a vastly improved compute architecture designed specifically to support next generation gaming effects such as raytracing, order-independent transparency, and fluid simulations.
Game performance and image quality receive a tremendous boost, and GF100 enables film-like geometric realism for game characters and objects. Geometric realism is central to the GF100 architectural enhancements for graphics, In addition, PhysX simulations are much faster, and developerscan utilize GPU computing features in games most effectively with GF100. In designing GF100, our goals were to deliver:
- Exceptional Gaming Performance
- First-rate image quality
- Film-like Geometric Realism
- A Revolutionary Compute Architecture for Gaming
Exceptional Gaming Performance
First and foremost, GF100 is designed for gaming performance leadership. Based on Fermi’s third generation Streaming Multiprocessor (SM) architecture, GF100 doubles the number of CUDA cores over the previous architecture.
The geometry pipeline is significantly revamped, with vastly improved performance in geometry shading, stream out, and culling. The number of ROP (Render Output) units per ROP partition is doubled and fillrate is greatly improved, enabling multiple displays to be driven with ease. 8xMSAA performance is vastly improved through enhanced ROP compression. The additional ROP units also better balance overall GPU throughput even for portions of the scene that cannot be compressed.
First-rate image quality
GF100 implements a new 32xCSAA antialiasing mode based on eight multisamples and 24 coverage samples. CSAA has also been extended to support alpha-to-coverage on all samples, enabling smoother rendering of foliage and transparent textures. GF100 produces the highest quality antialiasing for both polygon edges and alpha textures with minimal performance penalty. Shadow mapping performance is greatly increased with hardware accelerated DirectX 11 four-offset Gather4.
Film-like Geometric Realism
While programmable shading has allowed PC games to mimic film in per-pixel effects, geometric realism has lagged behind. The most advanced PC games today use one to two million polygons per frame. By contrast, a typical frame in a computer generated film uses hundreds of millions of polygons. This disparity can be partly traced to hardware—while the number of pixel shaders has grown from one to many hundreds, the triangle setup engine has remained a singular unit, greatly affecting the relative pixel versus geometry processing capabilities of today’s GPUs. For example, the GeForce GTX 285 has more than 150× the shading horsepower of the GeForce FX, but less than 3× the geometry processing rate. The outcome is such that pixels are shaded meticulously, but geometric detail is comparatively modest.
In tackling geometric realism, we looked to movies for inspiration. The intimately detailed characters in films are made possible by two key techniques: tessellation and displacement mapping. Tessellation refines large triangles into collections of smaller triangles, while displacement mapping changes their relative position. In conjunction, these two techniques allow arbitrarily complex models to be formed from relatively simple descriptions. Some of our favorite movie characters, such as Davy Jones from Pirates of the Caribbean were created using these techniques.
GF100’s entire graphics pipeline is designed to deliver high performance in tessellation and geometry throughput. GF100 replaces the traditional geometry processing architecture at the front end of the graphics pipeline with an entirely new distributed geometry processing architecture that is implemented using multiple “PolyMorph Engines” . Each PolyMorph Engine includes a tessellation unit, an attribute setup unit, and other geometry processing units. Each SM has its own dedicated PolyMorph Engine (we provide more details on the Polymorph Engine in the GF100 architecture sections below). Newly generated primitives are converted to pixels by four Raster Engines that operate in parallel (compared to a single Raster Engine in prior generation GPUs). On-chip L1 and L2 caches enable high bandwidth transfer of primitive attributes between the SM and the tessellation unit as well as between different SMs. Tessellation and all its supporting stages are performed in parallel on GF100, enabling breathtaking geometry throughput.
While GF100 includes many enhancements and performance improvements over past GPU architectures, the ability to perform parallel geometry processing is possibly the single most importantGF100 architectural improvement. The ability to deliver setup rates exceeding one primitive per clock while maintaining correct rendering order is a significant technical achievement never before done in a GPU.
Revolutionary Compute Architecture for Gaming
The rasterization pipeline has come a long way, but as games aspire to film quality, graphics is moving toward advanced algorithms that require the GPU to perform general computation along with programmable shading. G80 was the first NVIDIA GPU to include compute features. GF100 benefits from what we learned on G80 in order to significantly improve compute features for gaming.
GF100 leverages Fermi’s revolutionary compute architecture for gaming applications. In graphics, threads operate independently, with a predetermined pipeline, and exhibit good memory access locality. Compute threads on the other hand often communicate with each other, work in no predetermined fashion, and often read and write to different parts of memory. Major compute features improved on GF100 that will be useful in games include faster context switching between graphics and PhysX, concurrent compute kernel execution and an enhanced caching architecture which is good for irregular algorithms such as ray tracing, and AI algorithms. We will discuss these features in more detail in subsequent sections of this paper.
Vastly improved atomic operations performance allows threads to safely cooperate through work queues, accelerating novel rendering algorithms. For example, fast atomic operations allow transparent objects to be rendered without presorting (order independent transparency) enabling developers to create levels with complex glass environments.
For seamless interoperation with graphics, GF100’s GigaThread engine reduces context switch time toabout 20 microseconds, making it possible to execute multiple compute and physics kernels for each frame. For example, a game may use DirectX 11 to render the scene, switch to CUDA for selective ray tracing, call a Direct Compute kernel for post processing, and perform fluid simulations using PhysX.
Geometric Realism
Tessellation and Displacement Mapping Overview
While tessellation and displacement mapping are not new rendering techniques, up until now, they have mostly been used in films. With the introduction of DirectX 11 and NVIDIA’s GF100, developers will be able to harness these powerful techniques for gaming applications. In this section we will discuss some of the characteristics and benefits of tessellation and displacement mapping in the context of game development and high-quality, realtime rendering.
Game assets such as objects and characters are typically created using software modeling packages like Mudbox, ZBrush, 3D Studio Max, Maya, or SoftImage. These packages provide tools based on surfaces with displacement mapping to aid the artist in creating detailed characters and environments. Today, the artist must manually create polygonal models at various levels of detail as required by the various rendering scenarios in the game, required to maintain playable frame-rates. These models are meshes of triangles with associated texture maps needed for proper shading. When used in a game, the model information is sent per frame to the GPU through its host interface. Game developers tend to use relatively simple geometric models due to the limited bandwidth of the PCI Express bus and the modest geometry throughput of current GPUs.
Even in the best of game titles, there are geometric artifacts due to limitations of existing graphics APIs and GPUs. The result of compromising geometric complexity can be seen in the images below, from FarCry® 2. The holster has a heavily faceted or segmented strap. The corrugated roof, which should look wavy, is in fact a flat surface with a striped texture. Finally, like most characters in games, this person wears a hat, carefully sidestepping the complexity of rendering hair.

Using GPU-based tessellation, a game developer can send a compact geometric representation of an object or character and the tessellator unit can produce the correct geometric complexity for the specific scene. We’ll now go into greater detail discussing the characteristics and benefits of tessellation in combination with displacement mapping.
Consider the character below. On the left we see the quad mesh used to model the general outline of the figure. This representation is quite compact, even when compared to typical game assets. The image of the character in the middle was created by finely tessellating the description on the left. The result is a very smooth appearance, free of any of the faceting that resulted from limited geometry. Unfortunately this character, while smooth, is no more detailed than the coarse mesh. The image on the right was created by applying a displacement map to the smoothly tessellated character in the middle. This character has a richness of geometric detail that you might associate with film production.
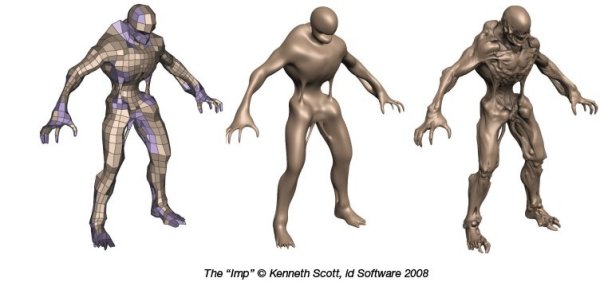
Benefits of Tessellation with Displacement Mapping
There are a number of benefits to using tessellation with displacement mapping. The representation is compact, scalable and leads to efficient storage and computation. The compactness of the description means that the memory footprint is small and little bandwidth is consumed pulling the constituent vertices on to the GPU. Because animation is performed on the compact description, more compute intensive, sophisticated, realistic movement is possible. The on-demand synthesis of triangles creates the ability to match the geometric complexity and the number of triangles generated to the situation for the specific character as it appears in a given frame.
This ability to control geometric level of detail (LOD) is very powerful. Because it is on-demand and the data is all kept on-chip, precious memory bandwidth is preserved. Also, because one model may produce many LODs, the same game assets may be used on a variety of platforms, from a modest notebook to a Quad SLI system for example.
The character can also be tailored to how it appears in the scene, if it is small hen it gets little geometry, if it is close to the screen it is rendered with maximum detail. Additionally, scalable assets mean that developers may be able to use the same models on multiple generations of games and future GPUs where performance increases enable even greater detail than was possible when initially deployed in a game. Complexity can be adjusted dynamically to target a given frame rate. Finally, models that are rendered using tessellation with displacement mapping much more closely resemble those used natively in the tools used by artists, freeing artists from the overhead work of creating models with different LODs.
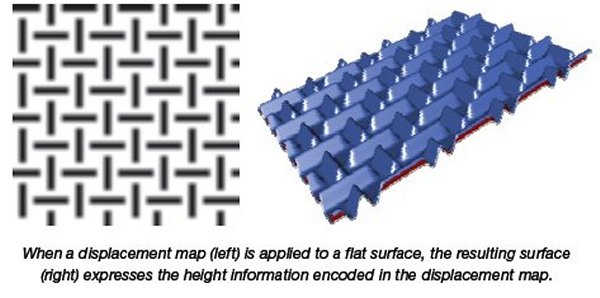
Displacement mapping is a very powerful modeling and rendering technique. A displacement map is a texture that expresses height information. When applied to a model, the displacement map is used to alter the relative position of vertices in the model. Displacement mapping allows complex geometry to be stored in a compact map. In this way, displacement maps can be regarded as a form of geometry compression.
Unlike emboss maps, normal maps, and parallax maps which merely alter the appearance of pixels, displacement maps alter the position of vertices. This enables self occlusion, accurate shadows, and robust behavior at the edges of silhouettes.
Displacement mapping is complementary to existing bump mapping techniques. For example, displacement maps can be used to define major surface features while finer grained techniques such as normal mapping are used for low level details such as scratches and moles.
In addition to being a simple way to create complex geometry, displacement mapped geometry also behaves naturally when animated. Consider the simple example to the right—the blunt spikes follow the base shape as it is bent. Displacement mapped characters behave similarly. Consider the Imp character on the preceding page. It is animated by manipulating the coarse control hull (left). The displacement mapped character (right) naturally follows the animation of the underlying surface.

Finally, one of the most interesting aspects of displacement maps is the ability to easily modify them during game play. In today’s games, spraying a metal door with bullets leaves a trail of bullet “decals”, but the shape of the door will not be altered. With displacement mapping, the same decal textures can be used to alter the displacement map, allowing a player to deform both the appearance and underlying structure of game objects.

GF100 Architecture In-Depth
GF100 GPUs are based on a scalable array of Graphics Processing Clusters (GPCs), Streaming Multiprocessors (SMs), and memory controllers. A full GF100 implements four GPCs, sixteen SMs and six memory controllers. We expect to launch GF100 products with different configurations of GPCs, SMs, and memory controllers to address different price points. For the purpose of this whitepaper, we will focus on the full GF100 GPU.
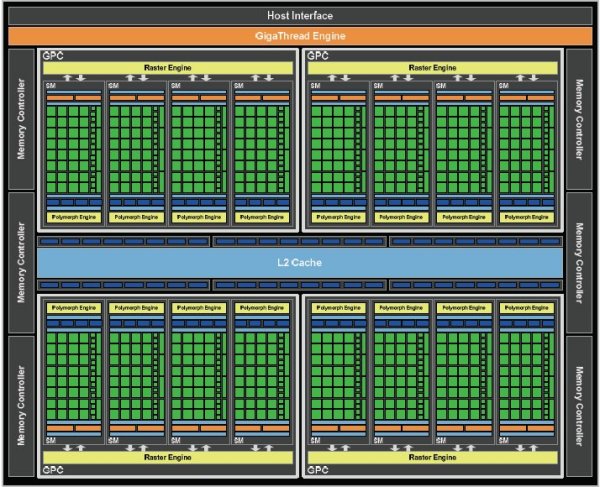
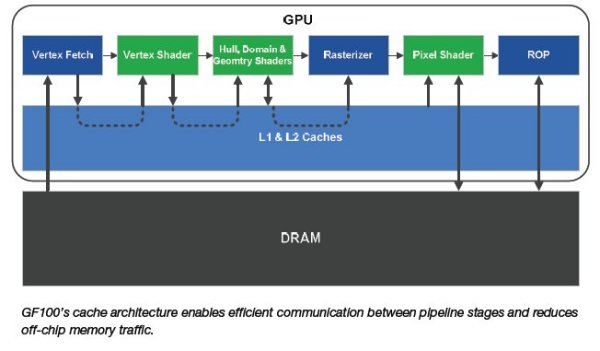
GF100 block diagram showing the Host Interface, the GigaThread Engine, four GPCs, six Memory Controllers, six ROP partitions, and a 768 KB L2 cache. Each GPC contains four PolyMorph engines. The ROP partitions are immediately adjacent to the L2 cache.
CPU commands are read by the GPU via the Host Interface. The GigaThread Engine fetches the specified data from system memory and copies them to the framebuffer. GF100 implements six 64-bit GDDR5 memory controllers (384-bit total) to facilitate high bandwidth access to the framebuffer. The GigaThread Engine then creates and dispatches thread blocks to various SMs. Individual SMs in turn schedules warps (groups of 32 threads) to CUDA cores and other execution units. The GigaThread Engine also redistributes work to the SMs when work expansion occurs in the graphics pipeline, such as after the tessellation and rasterization stages.
GF100 implements 512 CUDA cores, organized as 16 SMs of 32 cores each. Each SM is a highly parallel multiprocessor supporting up to 48 warps at any given time. Each CUDA core is a unified processor core that executes vertex, pixel, geometry, and compute kernels. A unified L2 cache architecture services load, store, and texture operations.
GF100 has 48 ROP units for pixel blending, antialiasing, and atomic memory operations. The ROP units are organized in six groups of eight. Each group is serviced by a 64-bit memory controller. The memory controller, L2 cache, and ROP group are closely coupled—scaling one unit automatically scales the others.
GPC Architecture
GF100’s graphics architecture is built from a number of hardware blocks called Graphics Processing Clusters (GPCs). A GPC contains a Raster Engine and up to four SMs.
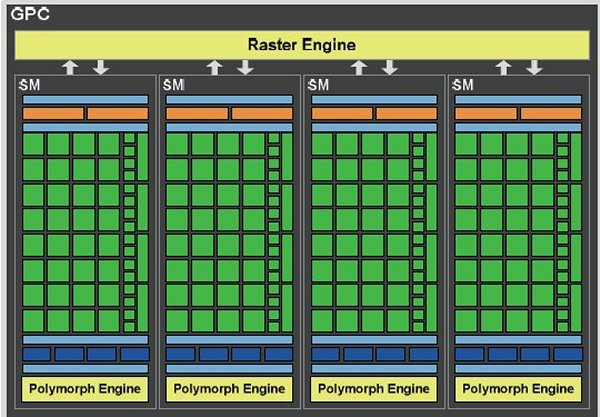
The GPC is GF100s dominant high-level hardware block. It features two key innovationsa scalable Raster Engine for triangle setup, rasterization, and z-cull, and a scalable PolyMorph Engine for vertex attribute fetch and tessellation. The Raster Engine resides in the GPC, whereas the PolyMorph Engine resides in the SM.
As its name indicates, the GPC encapsulates all key graphics processing units. It represents a balanced set of vertex, geometry, raster, texture, and pixel processing resources. With the exception of ROP functions, a GPC can be thought of as a self contained GPU, and a GF100 has four GPCs!
On prior NVIDIA GPUs, SMs and Texture Units were grouped together in hardware blocks called Texture Processing Clusters (TPCs). On GF100, each SM has four dedicated Texture Units, eliminating the need for TPCs. For simplicity, we will only refer to the SM going forward.
Parallel Geometry Processing
Previous GPU designs have used a single monolithic frontend to fetch, assemble, and rasterize triangles. This fixed pipeline provided a fixed amount of performance to an arbitrary number of parallel execution cores. As applications differ in their workload, this pipeline was often bottlenecked or underutilized. The difficulty of parallelizing rasterization while maintaining API order also discouraged major innovations in this area. While the single frontend design has worked well in past GPU designs, it became a major roadblock as the need for geometric complexity increased.
The use of tessellation fundamentally changes the GPU’s graphics workload balance. With tessellation, the triangle density of a given frame can increase by multiple orders of magnitude, putting enormous strain on serial resources such as the setup and rasterization units. To sustain high tessellation performance, it is necessary to rebalance the graphics pipeline.
To facilitate high triangle rates, we designed a scalable geometry engine called the PolyMorph Engine. Each of the 16 PolyMorph engines has its own dedicated vertex fetch unit and tessellator, greatly expanding geometry performance. In conjunction we also designed four parallel Raster Engines, allowing up to four triangles to be setup per clock. Together, they enable breakthrough triangle fetch, tessellation, and rasterization performance.
The PolyMorph Engine
The PolyMorph Engine has five stages: Vertex Fetch, Tessellation, Viewport Transform, Attribute Setup, and Stream Output. Results calculated in each stage are passed to an SM. The SM executes the game’s shader, returning the results to the next stage in the PolyMorph Engine. After all stages are complete, the results are forwarded to the Raster Engines.

The first stage begins by fetching vertices from a global vertex buffer. Fetched vertices are sent to the SM for vertex shading and hull shading. In these two stages vertices are transformed from object space to world space, and parameters required for tessellation (such as tessellation factor) are calculated. The tessellation factors (or LODs) are sent to the Tessellator.
In the second stage, the PolyMorph Engine reads the tessellation factors. The Tessellator dices the patch (a smooth surface defined by a mesh of control points) and outputs a mesh of vertices. The mesh is defined by patch (u,v) values, and how they are connected to form a mesh.
The new vertices are sent to the SM where the Domain Shader and Geometry Shader are executed. The Domain Shader calculates the final position of each vertex based on input from the Hull Shader and Tessellator. At this stage, a displacement map is usually applied to add detailed features to the patch. The Geometry Shader conducts any post processing, adding and removing vertices and primitives where needed. The results are sent back to the Tessellation Engine for the final pass.
In the third stage, the PolyMorph Engine performs viewport transformation and perspective correction. Attribute setup follows, transforming post-viewport vertex attributes into plane equations for efficient shader evaluation. Finally, vertices are optionally “streamed out” to memory making them available for additional processing.
On prior architectures, fixed function operations were performed with a single pipeline. On GF100, both fixed function and programmable operations are parallelized, resulting in vastly improved performance.
Raster Engine
After primitives are processed by the PolyMorph Engine, they are sent to the Raster Engines. To achieve high triangle throughput, GF100 uses four Raster Engines in parallel.

The Raster Engine is composed of three pipeline stages. In the edge setup stage, vertex positions are fetched and triangle edge equations are computed. Triangles not facing the screen are removed via back face culling. Each edge setup unit processes up to one point, line, or triangle per clock.
The Rasterizer takes the edge equations for each primitive and computes pixel coverage. If antialiasing is enabled, coverage is performed for each multisample and coverage sample. Each Rasterizer outputs eight pixels per clock for a total of 32 rasterized pixels per clock across the chip.
Pixels produced by the rasterizer are sent to the Z-cull unit. The Z-cull unit takes a pixel tile and compares the depth of pixels in the tile with existing pixels in the framebuffer. Pixel tiles that lie entirely behind framebuffer pixels are culled from the pipeline, eliminating the need for further pixel shading work.
Recap of the GPC Architecture
The GPC architecture is a significant breakthrough for the geometry pipeline. Tessellation requires new levels of triangle and rasterization performance. The PolyMorph Engine dramatically increases triangle, tessellation, and Stream Out performance. Four parallel Raster Engines provide sustained throughout in triangle setup and rasterization. By having a dedicated tessellator for each SM, and a Raster Engine for each GPC, GF100 delivers up to 8× the geometry performance of GT200.
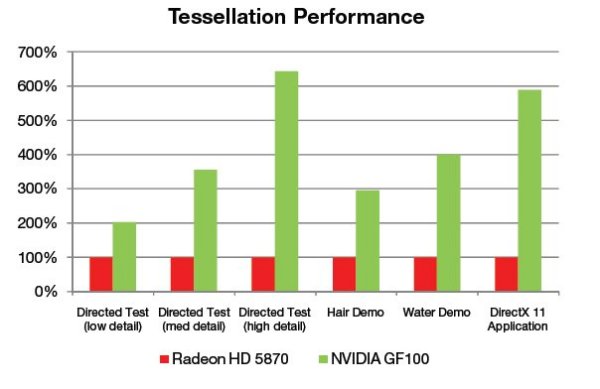
Note: We can’t help but insert a comment here. Whether you realize it or not most games use triangles for wire frames in every frame. That means there are hundreds/thousands/hundreds of thousands of triangles being processed for every frame of a game. Fermi is built to handle it and for the first time in GPU history the GPU isn’t stuck processing one triangle at a time. Fermi can (theoretically) produce 4 triangles at once. The reality is that it can process about 2.5 – 2.7 simultaneously. That might not seem like a lot but previous GPU’s processed one so even 2.5 per clock is a 250% polygon processing performance increase.
The left three bars in the chart show tessellated geometry performance for three directed tests that focus exclusively on tessellation performance. As geometric complexity is increased, GF100’s performance lead over the competition increases. The Hair and Water demos include both shading and compute operations in addition to geometry processing. The rightmost bar shows the performance of a tessellation state bucket (a set of draw calls from a frame) from a DirectX 11 application.

Another Note: If you think back in games you have played how many characters wore a bandanna were bald or wore a hat or had “Plastic hair”. The demo of the hair (we’ll link a Utube Later) was pretty amazing and while we are sure it will be demanding on GPU’s the amount of realism it will add is well worth the extra horsepower you’ll need.
Third Generation Streaming Multiprocessor
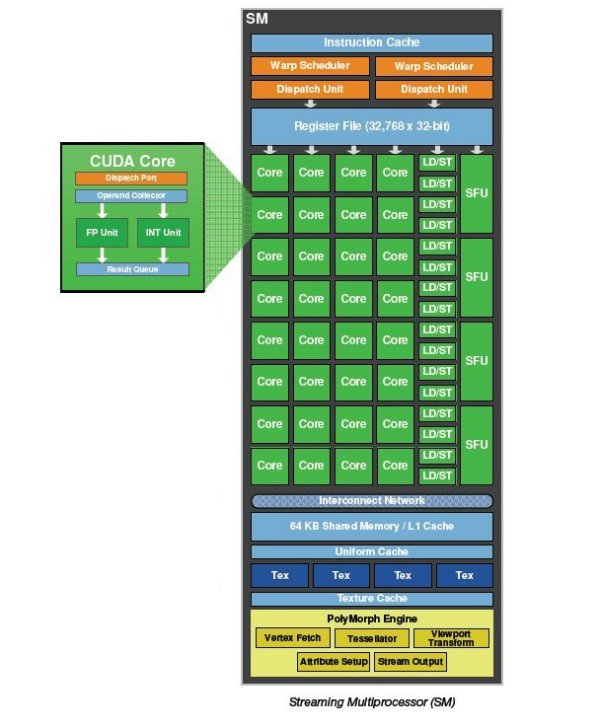
The third generation SM introduces several architectural innovations that make it not only the most powerful SM yet built, but also the most programmable and efficient.
512 High Performance CUDA cores
Each SM features 32 CUDA processors—a fourfold increase over prior SM designs. GF100’s CUDA cores are designed for maximum performance and efficiency across all shader workloads. By employing a scalar architecture, full performance is achieved irrespective of input vector size. Operations on the z-buffer (1D) or texture access (2D) attain full utilization of the GPU.
Each CUDA processor has a fully pipelined integer arithmetic logic unit (ALU) and floating point unit (FPU). GF100 implements the new IEEE 754-2008 floating-point standard, providing the fused multiply-add (FMA) instruction for both single and double precision arithmetic. FMA improves over a multiply-add (MAD) instruction by doing the multiplication and addition with a single final rounding step, with no loss of precision in the addition. FMA minimizes rendering errors in closely overlapping triangles.
In GF100, the newly designed integer ALU supports full 32-bit precision for all instructions, consistent with standard programming language requirements. The integer ALU is also optimized to efficiently support 64-bit and extended precision operations. Various instructions are supported, including Boolean, shift, move, compare, convert, bit-field extract, bitreverse insert, and population count.
16 Load/Store Units
Each SM has 16 load/store units, allowing source and destination addresses to be calculated for sixteen threads per clock. Supporting units load and store the data at each address to cache or DRAM.
Four Special Function Units
Special Function Units (SFUs) execute transcendental instructions such as sin, cosine, reciprocal, and square root. Graphics interpolation instructions are also performed on the SFU. Each SFU executes one instruction per thread, per clock; a warp (32 threads) executes over eight clocks. The SFU pipeline is decoupled from the dispatch unit, allowing the dispatch unit to issue to other execution units while the SFU is occupied. Complex procedural shaders especially benefit from dedicated hardware for special functions.
Dual Warp Scheduler
The SM schedules threads in groups of 32 parallel threads called warps. Each SM features two warp schedulers and two instruction dispatch units, allowing two warps to be issued and executed concurrently. GF100’s dual warp scheduler selects two warps, and issues one instruction from each warp to a group of sixteen cores, sixteen load/store units, or four SFUs. Because warps execute independently, GF100’s scheduler does not need to check for dependencies from within the instruction stream. Using this elegant model of dual-issue, GF100 achieves near peak hardware performance.
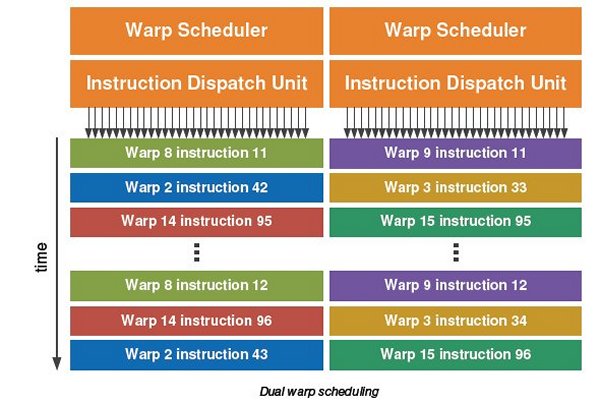
Most instructions can be dual issued—two integer instructions, two floating instructions, or a mix of integer, floating point, load, store, and SFU instructions can be issued concurrently. Double precision instructions do not support dual dispatch with any other instruction.
Texture Units
Each SM has four texture units. Each texture unit computes a texture address and fetches four texture samples per clock. Results can be returned filtered or unfiltered. Bilinear, trilinear, and anisotropic filtering modes are supported.
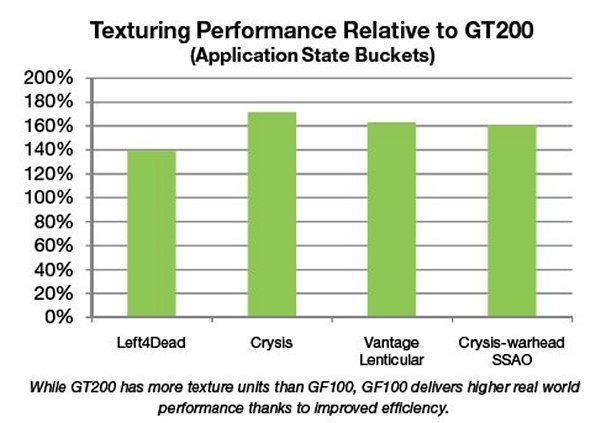
The goal with GF100 was to improve delivered texture performance through improved efficiency. This was achieved by moving the texture units within the SM, improving the efficiency of the texture cache, and higher clock speed.
In the previous GT200 architecture, up to three SMs shared one texture engine containing eight texture filtering units. In the GF100 architecture, each SM has its own dedicated texture units and a dedicated texture cache. Also, the internal architecture of the texture units has been significantly enhanced. The net effect is a significant improvement in the delivered texture performance in real-world use cases such as shadow mapping and screen space ambient occlusion.
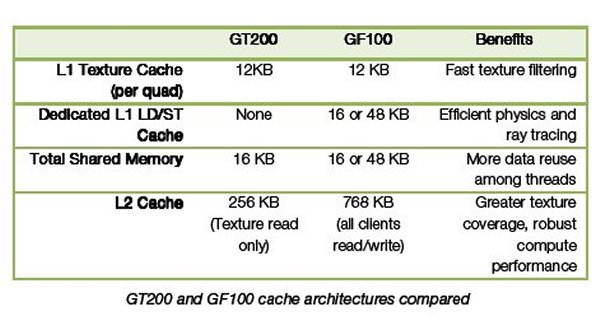
GF100’s dedicated L1 texture cache has been redesigned for greater efficiency. Further, by having a unified L2 cache, the maximum available cache available for texture is three times higher than GT200, improving hit rates in texture heavy shaders.
The texture unit on previous architectures operated at the core clock of the GPU. On GF100, the texture units run at a higher clock, leading to improved texturing performance for the same number of units.
GF100’s texture units also add support for DirectX 11’s BC6H and BC7 texture compression formats, reducing the memory footprint of HDR textures and render targets.
The texture units also support jittered sampling through DirectX 11’s four-offset Gather4 feature, allowing four texels to be fetched from a 128×128 pixel grid with a single texture instruction. GF100 implements DirectX 11 four-offset Gather4 in hardware, greatly accelerating shadow mapping, ambient occlusion, and post processing algorithms. With jittered sampling, games can implement smoother soft shadows or custom texture filters efficiently.
64 KB Configurable Shared Memory and L1 Cache
Shared memory—a fast, programmable on-chip memory, is one of the key architectural innovations of the first generation CUDA architecture. By facilitating inter-thread communication, shared memory enabled a broad range of applications to run efficiently on the GPU. Shared memory has since been adopted by all major GPU computing standards and competing architectures.
Recognizing the crucial role played by shared memory and the importance of maintaining data locality, we once again extended the GPU memory model. GF100 incorporates a dedicated L1 cache per SM.
The L1 cache works as a counterpart to shared memory—while shared memory improves memory access for algorithms with well defined memory access, the L1 cache improves memory access for irregular algorithms where data addressees are not known beforehand.
On GF100 GPUs, each SM has 64 KB of on-chip memory that can be configured as 48 KB of Shared memory with 16 KB of L1 cache, or as 16 KB of Shared memory with 48 KB of L1 cache.
For graphics programs, GF100 makes use of the 16 KB L1 cache configuration. The L1 cache acts as a buffer for register spills, allowing graceful performance scaling with register usage. For compute programs, the L1 cache and shared memory enables threads within the same thread block to cooperate, facilitates extensive reuse of on-chip data, and reduces off-chip traffic. Shared memory is a key enabler for many high-performance CUDA applications.
L2 Cache
GF100 has a 768 KB unified L2 cache that services all load, store, and texture requests. The L2 provides efficient, high speed data sharing across the GPU. Algorithms for which data addresses are not known beforehand, such as physics solvers, ray tracing, and sparse data structures especially benefit from a hardware cache. Post processing filters that require multiple SMs to read the same data require fewer trips to memory, improving bandwidth efficiency.
A unified cache is more efficient than separate caches. In a non-unified cache design, if one cache is oversubscribed, it cannot use the unmapped portions of other caches. Cache utilization will always be less than the theoretical peak. GF100’s unified L2 cache dynamically load balances between different requests, allowing full utilization of the cache. The L2 cache replaces the L2 texture cache, ROP cache, and on-chip FIFOs on prior GPUs.
A unified cache also ensures memory access instructions arrive in program order. Where read and write paths are separate (such as a read only texture path and a write only ROP path), read after write hazards may occur. A unified read/write path ensures program correctness, and is a key feature that allows NVIDIA GPUs to support generic C/C++ programs.
GF100 L2 cache is read/write and fully coherent compared to GT200 L2 cache which is read-only. Evicting data out of L2 is handled by a priority algorithm that includes various checks to help ensure needed data stays resident in the cache.
New ROP Units with Improved Antialiasing
GF100’s ROP subsystem has been redesigned for improved throughput and efficiency. One GF100 ROP partition contains eight ROP units, a twofold improvement over prior architectures. Each ROP unit can output a 32-bit integer pixel per clock, an FP16 pixel over two clocks, or an FP32 pixel over four clocks. Atomic instruction performance is also vastly improved—atomic operations to the same address execute up to 20 times faster than GT200, operations to contiguous memory regions execute up to 7.5 times faster.
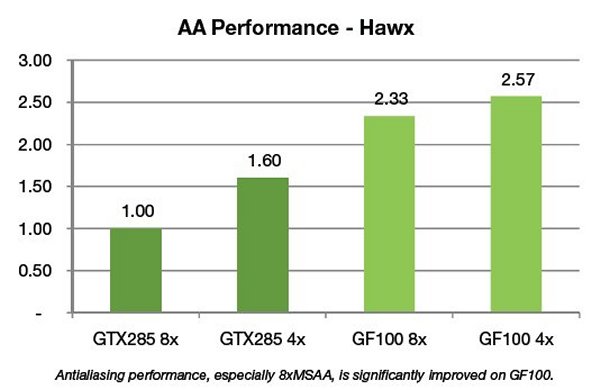
Performance for 8xMSAA is significantly increased on GF100 due in improvements in compression efficiency as well as additional ROP units that permit more effective rendering of smaller primitives that cannot be compressed. Increasing geometric realism in scenes increases the requirement for ROP units to perform well when compression is not active.
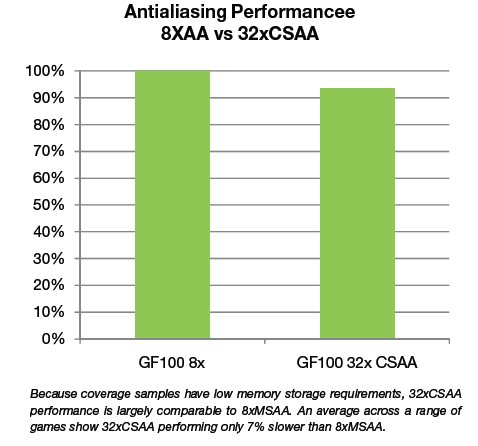
In the previous generation, performance drop in 8xMSAA modes varied significantly depending on the title; Tom Clancy’s HAWX is one example of a game that showed low efficiency in 8xMSAA. In GF100 the 8xAA performance is much improved. In 4xAA mode, GF100 is 1.6× faster than GT200. Comparing in 8xAA mode, GF100 is 2.3× faster than GT200, and only 9% slower than the GF100 4xAA mode.
GF100 has also invested in a new 32x Coverage Sampling Antialiasing (CSAA) mode to provide the highest image quality and improve the level of perceived geometric realism in current games using alpha-to-coverage.
Current games are constrained by the limitations of API and GPU horsepower in the amount of geometry they can render. Foliage is a particular challenge. A common technique for foliage is to create an alpha textured billboard containing many leaves, using alpha to coverage to eliminate the gaps between the leaves. The quality of the edge is determined by the number of coverage samples. In cases with only four coverage or even eight samples available, very objectionable aliasing and banding results, especially when the texture is close to the screen. With 32x CSAA, the GPU has 32 total coverage samples available, minimizing banding effects.
Transparency Multisampling (TMAA) also benefits from CSAA. TMAA benefits DirectX 9 games that are unable to use alpha-to-coverage directly because it is not exposed in the DirectX 9 API. Instead they use a technique called “alpha test” which produces hard edges for transparent textures. TMAA converts the old shader code in the DirectX 9 applications to use alpha-to-coverage, which combined with CSAA, produces greatly improved image quality.
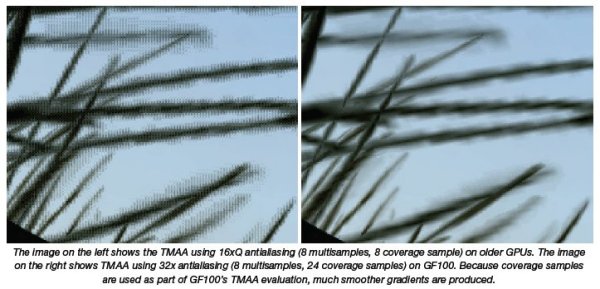
Compute Architecture for Graphics
The vast improvements in per-pixel realism in recent years were made possible by programmable shaders. Going forward, programmability will continue to be of overriding importance in allowing developers to create next generation visual effects.
Computer graphics is a set of diverse problems with numerous approaches. Rasterization, ray tracing, and Reyes are well recognized general rendering algorithms. Within each style of rendering, different solutions exist for various sub-problems. Up until now, the GPU has been designed solely for rasterization. As developers continue to search for novel ways to improve their graphics engines, the GPU will need to excel at a diverse and growing set of graphics algorithms. Since these algorithms are executed via general compute APIs, a robust compute architecture is fundamental to a GPU’s graphical capabilities. In essence, one can think of compute as the new programmable shader.
G80 was NVIDIA’s first compute architecture. Its design reflected the desire to extend the GPU’s capabilities to solve HPC style problems. For example, one of G80’s key innovations, shared memory, was instrumental in accelerating matrix multiplication, the basis of many math and physics algorithms.
GF100’s compute architecture is designed to address a wider range of algorithms and to facilitate more pervasive use of the GPU for solving parallel problems. Many algorithms, such as ray tracing, physics, and AI, cannot exploit shared memory—program memory locality is only revealed at runtime. GF100’s cache architecture was designed with these problems in mind. With up to 48 KB of L1 cache per SM and a global L2 cache, threads that access the same memory locations at runtime automatically run faster, irrespective of the choice of algorithm.
Another area of improvement in GF100’s compute architecture for gaming is in scheduling. G80 and GT200 executed large kernels one at a time with relatively slow context switching. Since HPC applications employ large data sets and are insensitive to latency, this model worked relatively well. In gaming applications, no single kernel dominates, but various small kernels (cloth, fluid, and rigid bodies for example) are executed. On GF100, these kernels execute in parallel, enabling maximum utilization of CUDA cores.
In games that make use of compute, context switches occur at every frame, making their performance highly critical to responsive framerates. GF100 reduces context switch time down to about 20 microseconds, making it possible to perform fine-grained context switching between multiple kernels per frame. For example, a game may use DirectX 11 to render the scene, switch to CUDA for selective ray tracing, call a Direct Compute kernel for post processing, and perform fluid simulations using PhysX.
As developers make more general use of the GPU, better language and debugging support becomes crucial. GF100 is the first GPU to offer full C++ support, the language of choice among game developers. To ease the transition to GPU programming, we’ve also developed Nexus—a Microsoft Visual Studio programming environment for the GPU. Together with new hardware features that provide better debugging support, developers will be able enjoy CPU-class application development on the GPU.
Next Generation Effects using GPU Computing
Because compute algorithms are general in nature, they can be used to solve a large variety of visual computing and simulation algorithms. Some examples game developers are looking into for their upcoming games include:
- Novel rendering algorithms
- Ray tracing for accurate reflections and refractions
- Reyes for detailed displacement mapping and high quality antialiasing
- Voxel rendering for simulation of volumetric data
- Image processing algorithms
- Custom depth of field kernels with accurate out of focus highlights (bokeh)
- Histograms for advanced HDR rendering
- Custom filters for advanced blurring and sharpened effects
- Physical simulations
- Smoothed partical hydrodynamics for advanced fluid simulation
- Turbluance for detailed smoke and fluid effects
- GPU Rigid bodies for pervasive use of physical objects
- AI pathfinding algorithms for greater number of characters in-game
In the following section, we look at two examples in depth: ray tracing, and smoothed particle hydrodynamics.
Ray tracing
Ray tracing is seen by many as the future of graphics, either by itself or in conjunction with rasterization. With GF100, interactive ray tracing becomes possible for the first time on a standard PC.
Ray tracing has typically been challenging to run efficiently on the GPU. Ray tracing operates recursively, whereas GPUs mostly operate iteratively. Rays have unpredictable directions, requiring lots of random memory access. GPUs typically access memory in linear blocks for efficiency.
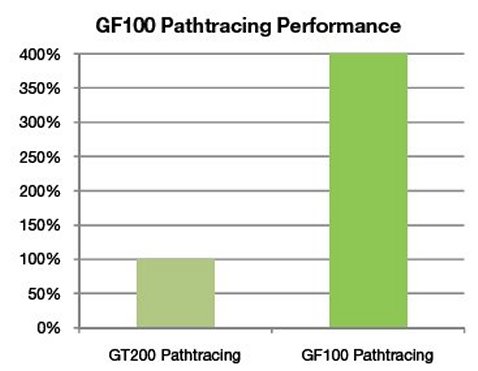
GF100’s compute architecture was built specifically with ray tracing in mind. GF100 is the first GPU to support recursion in hardware, enabling efficient ray tracing and a host of other graphics algorithms. GF100’s L1 and L2 caches greatly improve ray tracing efficiency by improving performance for fine-grained memory accesses. The L1 cache enhances memory locality for neighboring rays whereas the L2 cache amplifies bandwidth to the framebuffer.
GF100 excels not just at standard ray tracing, but also at advanced global illumination algorithms such as path tracing. Path tracing uses a much larger number of rays to collect ambient lighting information from the scene. Early evaluations of path tracing show GF100 performing up to four times faster than GT200.

To sustain performance, a game may use ray tracing selectively. For example, rasterization can be used to perform a first pass on the scene. Pixels that are identified as reflective may be further processed via ray tracing. This hybrid model of rendering enables fast performance with great image quality.
Smoothed Particle Hydrodynamics (SPH)
Realistic fluid simulations have long been used in film to create novel characters and dramatic effects. T- 1000 in Terminator 2: Judgment Day was created with computer generated “liquid metal.” Simulation of vast bodies of water was crucial to achieving the climatic shots in 2012. While game designers aspire to similar effects, the computational complexity of fluid simulations has prevented their use in realtime applications.
In 2003, Müller et al. adopted smoothed particle hydrodynamics (SPH), an astrophysics algorithm, for interactive fluid simulations. Their initial work demonstrated 5,000 SPH particles, enough to simulate a pouring glass of water at 5 frames per second. Muller’s SPH algorithm has since been integrated into the PhysX API. The first game that made use of PhysX SPH, Cryostasis, simulated 30,000 water particles at 30 frames per second on the GT200 architecture. Although a technological breakthrough for its time, the water in Cryostasis lacked the particle count to achieve convincing fluidity, and the high cost of interoperating with graphics limited real world performance.

GF100 is the first GPU to deliver the performance required for high fidelity fluid simulations, and together with an improved SPH solver, enables games designers to incorporate high quality SPH fluid throughout game environments. GF100 is able to simulate over 128,000 SPH particles per frame—sufficient to support large volumes of water and a range of fluid based effects. For example, SPH can be used to model rain, allowing the natural formation of splashes, puddles, and overflow. With different parameters, SPH can be used for blood, which has higher viscosity and different dripping characteristics. In both cases, fluid behavior is based on physical models, guaranteeing consistency and realism.
The SPH algorithm typically does not make use of shared memory, which has constrained performance on last generation architectures. GF100’s robust cache architecture greatly reduces off-chip memory traffic, allowing large number of particles to be simulated without saturating memory bandwidth. Fast context switching further reduces simulation overhead. Thanks to these improvements, GF100 is able to perform SPH simulation together with graphics rendering at over 140 frames per second.
NVIDIA 3D Vision Surround
NVIDIA 3D Vision is a combination of high-tech wireless glasses and advanced software that automatically transforms games (400+ and counting) into full stereoscopic 3D.
Powered by GF100 GPUs in NVIDIA SLI configuration, the upcoming NVIDIA 3D Vision Surround technology takes 3D gaming to an entirely new level by delivering fully immersive IMAX 3D-like gaming across three monitors in full stereoscopic 3D.

NVIDIA 3D Vision Surround uses up to 746 million pixels per second of rendering horsepower, or 3x greater than last generation’s extreme gaming setup. With tessellation, compute shaders, and PhysX enabled, the demand on the GPU is tremendous. GF100 is architected to enable the highest performance on NVIDIA 3D Vision Surround. GF100’s new ROP subsystem has twice as many ROP units per partition, allowing multiple displays to be fed concurrently. Its parallel tessellation and raster engines enable sustained performance in heavily tessellated scenes. And its powerful compute architecture with fast context switching makes compute operations as lightweight as possible.


GF100 supports 3D Vision Surround when two or more GPUs are paired in a SLI configuration. 3D Vision Surround will be supported across three of the same 3D Vision capable LCDs and projectors at resolutions up to 1920×1080. For those not ready to jump into stereoscopic gaming, NVIDIA Surround will also be supported in non-stereoscopic 3D at resolutions up to 2560 x 1600 across displays that share a common resolution.
Bezel Correction
NVIDIA 3D Vision Surround includes controls that allow for the adjustment of the displays to compensate for monitor bezel gaps, allowing for a more realistic viewing of full-screen games. With bezel correction, part of the game view is hidden behind the display bezel so that the bezel appears to be part of the game. This produces a more continuous image across the displays and provides a more realistic experience. It is similar to looking through a cockpit window where the window frames block your view.
Conclusion
PC gaming has been NVIDIA’s core passion for sixteen years. With GF100, we continue this commitment to the advancement of 3D graphics and PC gaming.
With up to sixteen tessellation engines and four raster engines, GF100 elevates geometric realism to new heights. Tessellation and displacement mapping—the key techniques employed in films, becomes a reality for the first time in PC gaming. Characters with life-like detail, game environments with unprecedented complexity, that’s what GF100 promises to gamers.
In the pursuit of computational graphics, we have been equally ambitious. GF100 is the world’s first and only GPU to support C/C++, recursion, and cached read and writes. Together these features enable game developers to solve the hardest problems of graphics, including ray tracing, order independent transparency, and physics simulations. Once gamers experience the fidelity and consistency brought by computational graphics, the representational effects of the past will seem as aged as fixed function graphics.
Behind all our efforts is the belief that PC gaming is unique. Today’s games are multiplatform by design, but it is on the PC that they reach their fullest expression. With GF100, we hope to continue to push the boundaries of PC gaming, and make it the world’s most powerful and dynamic gaming platform.
With the graphics and compute horsepower of GF100, we’ve extended NVIDIA 3D Vision to three monitors, enabling the most immersive gaming experience possible.
With its amazing performance, groundbreaking geometry engine, and world class architecture for computational graphics, GF100 represents a landmark for 3D graphics and PC gaming.
Notice
ALL INFORMATION PROVIDED IN THIS WHITE PAPER, INCLUDING COMMENTARY, OPINION, NVIDIA DESIGN SPECIFICATIONS, REFERENCE BOARDS, FILES, DRAWINGS, DIAGNOSTICS, LISTS, AND OTHER DOCUMENTS (TOGETHER AND SEPARATELY, “MATERIALS”) ARE BEING PROVIDED “AS IS.” NVIDIA MAKES NO WARRANTIES, EXPRESSED, IMPLIED, STATUTORY, OR OTHERWISE WITH RESPECT TO MATERIALS, AND EXPRESSLY DISCLAIMS ALL IMPLIED WARRANTIES OF NONINFRINGEMENT, MERCHANTABILITY, AND FITNESS FOR A PARTICULAR PURPOSE.
Information furnished is believed to be accurate and reliable. However, NVIDIA Corporation assumes no responsibility for the consequences of use of such information or for any infringement of patents or other rights of third parties that may result from its use. No license is granted by implication or otherwise under any patent or patent rights of NVIDIA Corporation. Specifications mentioned in this publication are subject to change without notice. This publication supersedes and replaces all information previously supplied. NVIDIA Corporation products are not authorized for use as critical components in life support devices or systems without express written approval of NVIDIA Corporation.
Trademarks
NVIDIA, the NVIDIA logo, CUDA, FERMI, and GeForce are trademarks or registered trademarks of NVIDIA Corporation in the United States and other countries. Other company and product names may be trademarks of the respective companies with which they are associated.
Copyright
© 2010 NVIDIA Corporation. All rights reserved.
Nvidia’s Bad Rap
We’ve been hearing, from uninformed sources, that Nvidia has been heavy handing code in games to make Nvidia GPU’s run better and in the process making ATI’s GPU’s run worse. We’ve known all along that belief is ludicrous. First of all game developers are acutely aware of how ATI GPU’s perform on their games and if Nvidia were to deliberately decrease performance on the competitions offering they would never have the trust of the game developer again.
We were quite pleased that Nvidia took the time to address the rumors at our meeting in Las Vegas. While we knew that Nvidia offered game developers help in optimizing games for Nvidia GPU’s we didn’t know that as a result of that they often increase the performance and feature set of ATI GPU’s in the process. Yes you heard it right, Nvidia is so committed to gaming and delivering the best experience that they have optimized and added features for ATI GPU’s. So in an attempt to lay the rumors that Nvidia is buggering ATI’s performance to make their GPU’s look better we collected some hard data at the meeting and are presenting it to you here.

The first slide in the deck is just an introductory slide letting you know he general topic.

The developers engagements slide is basically the mission statement for Nvidia’s optimization team. First they want to make the game better for end users and easier for developers. Second do no harm, by that they mean ensure performance isn’t hurt (for Nvidia or ATI). Third make it easy for the developers to implement changes in their engine for the game and future games. Then last ensure that the games work well with the GPU.

Star Tales which admittedly wasn’t a huge title here in the US used UnrealEngine3 and the native engine didn’t have AA capabilities. Nvidia’s optimization team added support for AA to UnrealEngine3 and added it for both Nvidia and ATI GPU’s. Keep in mind this isn’t a money making operation. Nvidia doesn’t get paid for helping optimize games they lose money in man hours spent optimizing but feel that if it makes the games better more people will play and in the end buy and use more GPU’s. This good for the end user, good for gaming, good for GPU vendors and shows Nvidia’s commitment to makeing the end users experience better in a unique light.

Once Nvidia got wind that AA didn’t work on AMD GPU’s they found out it was because the AMD offerings didn’t support G16R16 and that the developers didn’t have any AMD GPU’s to verify the issue. Nvidia bought the developers ATI hardware so they could test. Once developers had a DX10 card in hand they implemented a workaround to get AA working on Star Tales. That doesn’t sound like Nvidia is decreasing performance for ATI to us. Quite the contrary they increases ATI’s worth in Star Tales so the end user could have a better experience.

When Nvidia was ask to help with Batman Arkham Asylum they wanted to add PhysX and make it spectacular. They also wanted to add 3D support (We can tell you from personal experience that the 3D and PhysX in Batman rock hard). They wanted optimal performance on all GPU’s with and without PhysX. Then they wanted to max out the eye candy to make an already good game better.
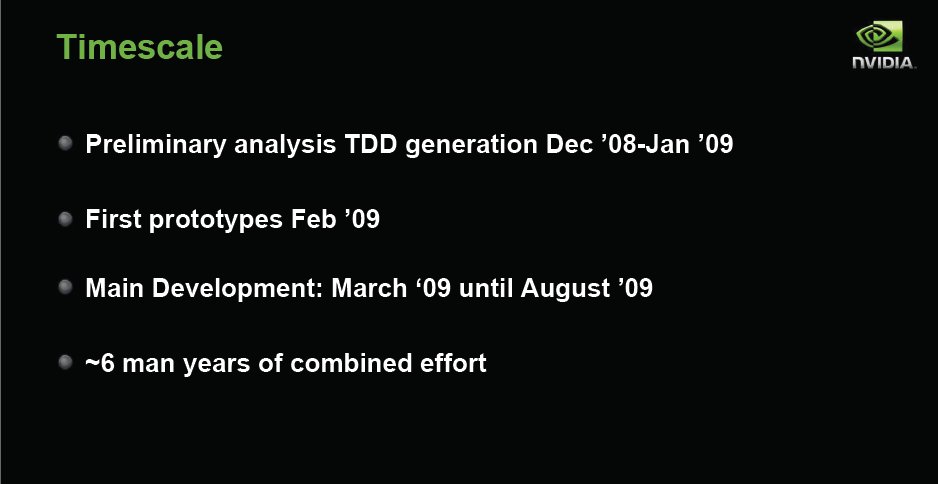
They started optimizing and implementation in January 2008, 13 months later in February 2009 they had prototypes ready. They spent March through August of 2009 in development. Total Nvidia investment in Batman was 6 man years of effort. Figure one highly paid mans wages for 6 years to optimize Batman Arkham Asylum and they didn’t get paid a dime up front. That’s commitment to making games better. Believe us when we tell you they worked some magic with Batman, we’ve played with and without PhysX and with and without 3D and with 3D and PhysX the game jumps to live and is much more enjoyable to play.

Nvidia is of course vested in PhysX and 3D Vision and they wanted to make the PhysX and 3D Vision pop for people using Nvidia GPU’s. Can’t blame them there its their proprietary technology. They spent 6 man years of labor doing just that and in the process realized they needed to be able to do it faster and let the game artists take part of the load.
To that end they developed APEX which is a front end coder that is easy enough for game artists to use to include PhysX in their games and decrease the man hours required to add PhysX. How much does APEX cost? Apex is free but if the developer wants dedicated support on using it there is a minimal charge for APEX support, how minimal about $300 (USD). They also wanted to implement GPU rigid bodies and self shadowed smoke. By that they mean smoke that has shadows that look real and not just a skinned shadow that doesn’t look right.

The bottom left panel in this shot shows smoke that has a skinned shadow, not very realistic and while you may not notice it in a fast paced game your brain will even if it’s on an unconscious level. The right panel is smoke that self shadows and looks much more natural.

UnrealEngine even in it’s 3rd iteration UnrealEngine3 isn’t what you would call up to snuff so Nvidia had to make it capable of rendering 3D and in the process gave the code to Epic so they can implement it in future UnrealEngine releases. Considering that the optimization team isn’t a for profit operation you can see Nvidia’s commitment to gaming. They are willing to spend the time, effort and yes money to make games better and provide developers and gaming engines with better tools to make games better.

In the process of working on Batman Nvidia learned and implemented a few great things. They learned you can create games designed for PhysX on every level. Refined the game engine technology so the developers can get feasible production times out of it and deployed new technology. In the end it’s the game developers and end users that benifit. Why do they do it, to make games better so more people will want to play on the PC and they benefit on the back end by selling more GPU’s.

Mirror’s Edge Nvidia’s optimization team removed unnecessary surface copies and provided shader optimizations. They patched the game for DX9 on UnrealEngine3 for Nvidia and ATI and added CSAA for Nvidia GPU’s. They improved lightmap filtering and added PhysX.

They modified the UE3 generic postprocessing and removed redundant StretchRects and optimized tonemapping. In the process they improved the performance of both Nvidia and ATI GPU performance. Often optimizing for one GPU has a positive effect on both camps GPU’s. Think of it in automobile terms, provide a better fuel and it doesn’t matter what engine you use the fuel in they all run better.
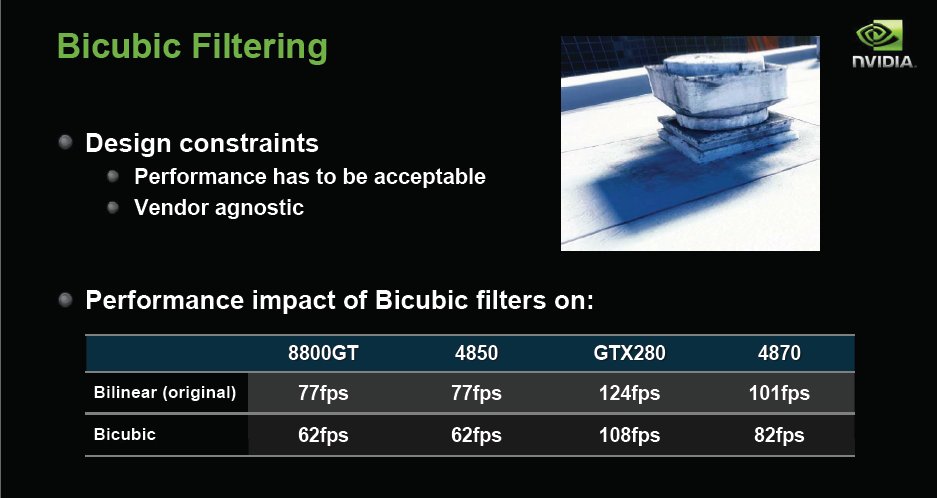
There’s always two edges to the new feature sword. We all know about the jaggy edges in games and frankly they are annoying. Bilinear filtering runs faster but you get jaggy edges so Nvidia came up with Bicubic Filtering to rid us of so many jagged edges. Bicubic rendering requires more raw horsepower and it decreases FPS performance slightly on both camps GPU’s but Nvidia was simply using the extra power of the GPU’s to provide a better gaming experience and provide a better gaming experience no matter the GPU camp you reside in.

The end result of Bicubic filtering. The left panel shows the dreaded jagged edges and the right panel shows a more natural looking smoother edge. Might be a small improvement but in gaming it’s the conglomeration of small improvements that make it more life like. The big changes like PhysX and 3D are eye popping but improving things on a base level makes for a better end user experience all around.

Lets get into a little PhysX and APEX information. PhysX is a fancy name for using realistic mathematical equations to predict how a in game object will act or react and provide eye candy in the process. Think Mage casting a spell, spell hits opponent and a little flash goes off and the opponent is hurt. PhysX version of that cast the same spell, spell hits opponent, sparks fly and bounce, opponent is damaged, sparks dissipate. Visually it’s more what you expect. You don’t toss a fireball and not expect flames to lick and smoke to trail. PhysX makes the flames and smoke realistic. Sure you can play the game without it but you can also marry someone without loving them but it’s not an attractive option. What’s the song song say, “Love and Marriage they go together like a horse and carriage this I tell ya brother games without PhysX are like kissing your mother.” Ok so maybe we took a little artistic leap there but you get the idea.

PhysX adds eye candy and realism to games and Nvidia needed a way to give the PhysX capabilities to the game developers and game artists to make it easier and less time consuming. To do that they designed a software framework and GUI called Apex so PhysX could be put in the hands of the game artist/developer and implemented easily. We saw a APEX demo and while it does have a learning curve it puts the creative control back into the hands of the game artists. Normally the game artist designs the character and if they want the character to do something they turn it over to the game engineer. APEX lets the game artist follow their vision and keep creative control from becoming an interdepartmental collaboration. Eliminate the back and forth and development happens faster and the artist retains more creative control. We have a Beta Dark Void in house, wait until you see what APEX has done for Dark Void and you will be a believer. Oh wait a minute you’ll, of course need an Nvidia GPU to experience the full depth of the game. We’ve played without PhysX and it’s not as life like, toss in some Nvidia 3D Vision and it’s so addictive it should have labeling from the FDA stating that continued use may lead to serious addiction.
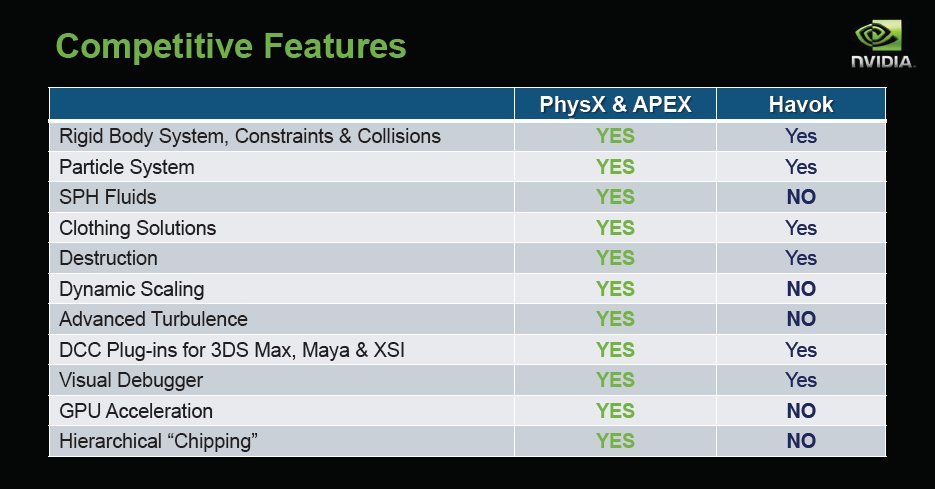
PhysX Vs Havoc feature sets. First PhysX runs on the GPU and currently Havoc runs on the CPU. Put to much Havoc in and the game bogs down so effects are pretty limited. Lets just touch on what PhysX has that Havoc doesn’t and let the chart tell you the rest. PhysX has SPH fluids (more real fluid movement), Dynamic scaling so the power you have available is taken into consideration PhysX isn’t going to run 100MPH when you have a GU that does 80MPH. PhysX also has advanced turbulence, now at first you think “So what”. Think of it this way the turbulence from a jet engine can flip a large vehicle, it can also affect smoke, paper on the ground, and it interacts with everything in the environment. Without advanced turbulance you can get physical effects in the surrounding environment but htay are pre-programmed and the same thing happens every time. PhysX allows the interaction between turbulence and the environment to act like it does in real life (or as close as modern computations will allow it to get). Like we mentioned PhysX runs on the GPU Havoc runs on the CPU, CPU’s are good at serial operations GPU’s are good at Parallel operations and PhysX lends itself to parallel operations. CPU’s bog down with heavy applications of Havoc GPU’s can provide a lot more effects using parallel processing and PhysX. Hierarchical chipping, at first we were like what the heck is that, it’s how things come apart. Specifically speaking imagine a large 50Cal bullet hitting a crumbling adobe wall, CPU PhysX you get 3 or 4 large chunks and several smaller chinks, GPU PhysX you get large chunks and as many smaller chunks as it takes to make it look real.

Apex currently has 4 modules, Clothing, Particles, Destruction and Vegetation. If we had to bet we would bet on more modules to expand APEX’s scope as the technology matures.

What should we take away from all this. Well for one thing Nvidia doesn’t deliberately bugger ATI performance. They spend money to make games better with no expectation of a real monetary gain for doing it. Nvidia wants to enrich the gaming experience for all end users. They want to make it possible for all platforms to use the technology. Then they want to make it easier to use so it gains greater acceptance. In short they aren’t taking anything away from Non-Nvidia users and often enrich their experience as well but in the end provide a richer more realistic experience for people with PhysX and 3D Vision. That’s just good business PhysX isn’t cheating it’s just a different way of doing more. We can’t make you believe that Nvidia doesn’t bugger ATI performance but it flys in the face of common sense, hurting gaming in general hurts everyone Nvidia included.
GF100 Design & Why
At some point in technology you have to look at what the end user wants, and what the vendors providing the technology are giving. Often you find technology partners saying here’s what we have and here’s what you are limited to doing with it. By the same token hardware developers have to look at where the industry is going and plan for giving what the developers need to give the end user more. With manufacturing technology advancing almost as fast as the desire for it, hardware vendors are looking more at what the hardware needs to do the job more efficiently and to deliver a more targeted product to adhere to today’s needs.
Nvidia is no exception to that cycle. They are however well tuned to the wants and needs of both developers and end users. To that end the technology packaged in Fermi (GF100) is tailored to today’s needs and not just a more powerful refresh of the GT200 core. You can get more raw power by tossing more transistors and hardware at the problem but if that raw power doesn’t do the job it needs then it’s just wasted raw power. Fermi addresses raw power but it’s more focused to doing what it needs to do to deliver a great end user/developer platform than previous Nvidia cores. Nvidia uses this concept to make a great core into a newer shinier redesigned core that delivers more raw power and the ability to excel at exactly what games need.

Like usual the first slide in the deck is just and introduction to the topic heading and of course a cool peek at the core itself.

This slide lets us know what Fermi is targeting. First and high on the scale of importance Geometric Realism. If you’ve been paying attention that’s usually accomplished with tons and tons of triangles hung as wireframes. Previous generations of GPU’s were serial triangle producers and could only generate one triangle per clock cycle. Fermi can theoretically produce 4 but in reality it can parallel produce 2.5 – 2.7 triangles per clock cycle. Tessellation takes the triangles on a wire frame and breaks the larger triangles into smaller triangles and that increases the load on the geometric portion of the GPU and was creating a bottleneck. Fermi parallel produces triangles and is Nvidia’s solution to that bottleneck.
Tessellation is by no means a new technology but game developers can’t produce Film like Tessellation because of the limitations of the geometry portion of existing GPU’s. Special effect houses for the film industry often use millions of triangles per frame, they however have the advantage of being able to spend copious time on each frame. GPU’s have a fraction of a second to render a whole frame and the Parallel geometry processing of Fermi is exactly what the game developers need to produce a more film like polished game.
This is, of course, a large investment and gamble on Nvidia’s part. How many of the technologies of yesteryear are still around. Game developers have to pick up Tessellation and utilize it or the gamble may not pay off. We’ve seen Tessellation in action and if game developers don’t adopt it then they obviously need professional help. Speaking of Tessellation check out the YouTube of Hair Tessellation we’ve linked in below.
In a lot of games you see a profusion of hats and bald people, hair is very hard to simulate and it’s GPU Tesselation and PhysX intensive. You can imagine the number of hairs on your head and making them react naturally with the surrounding environment (and looking real) and how hard that would be for a CPU or GPU to make look real. It’s still GPU intensive but Fermi’s design might end up being the Rogaine of computer technology. Hopefully we’ll be seeing fewer hats and plastic hair in the near future.

Fermi (GF100) features 512 Cuda Cores, 16 Geometry units, 4 Raster Units, 64 texture units, 48 ROP units and sports a 384 bit memory bus fed by GDDR5 memory. Previous top end Nvidia GPU’s had a wider 512bit Bus for GDDR3 memory. GDDR5 is faster so they can get away with a narrower bus. Compared to the AMD setup on top end GPU;s this is pretty generous, ATI has a 256bit bus for GDDR5, Nvidia is driving 50% more memory bus on the same GDDR5. We ask about the narrower bus on Fermi and faster GDDR5 and a wider bus would have made it more expensive was the answer we got.
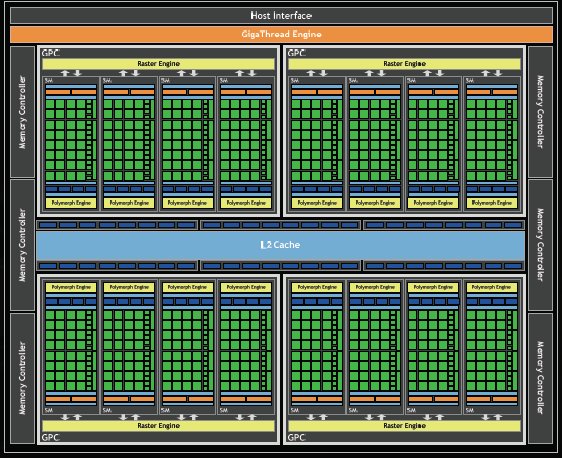
For those among you that drool over block diagrams we included a little bigger shot of the design.

Now take a look at the gun holster in the bottom left pane in this shot and you can see that instead of being naturally rounded like leather holsters are it has a little geometric angling. That’s a trade off between power available and desired detail. Fermi is designed to address this exact problem. Notice the traditional bandanna covering the expected plastic hair.

Now take this guy from Pirates of the Caribbean produced in a film studio where each frame is carefully Tessellated and displacement mapping is the defacto standard. Of course like we mentioned earlier the studio can spend hours on one frame while the GPU has a fraction of a second to do the same thing. The end result of the heavy Tessellation and displacement mapping is a much more realistic character which is required for film to make it more believable and realistic. GPU’s starting with Fermi are moving that direction and with it’s massively increased raw power and laser focus on geometric realism Nvidia GPU’s are heading for more realistic film like gaming. With GU power doubling about every 12 months it shouldn’t be long before we see film like video games if the game developers are up to the task.

Tessellation, like we explained earlier, is the process of using triangles for wireframe designs. Back in the day some called it polygon processing and games with it featured very angled unrealistic surfaces and creatures. GPU’s have vastly improved since then and they still use triangles for wire frames but they use a lot more of them now than back in the fledgling days of polygon programming. Tessellation is a major improvement on polygon wireframes, it takes the triangles on a wireframe and breaks them down into a multitude of smaller triangles making the image look smoother and rounder. With that increase in the number of triangles you increase the bottleneck of the previous generations serial production of triangles. Fermi, like we mentioned before, is the first GPU designed to parallel produce the triangles decreasing that bottleneck dramatically. We say decreasing because if hardware vendors deliver it game developers can overwhelm it (Think Crysis).

Displacement mapping, this is a hard concept unless you’ve studied it a little. Displacement mapping allows game developers to take what would be a flat pattern on the screen and give it depth or projection. To raise or lower a surfaces appearance. See the example below.
In the example you can see the raised surface created from displacement mapping. What that means to gaming is that flat surfaces with a shaded skin can now give a more realistic appearance of being raised. Move on to the next image and you get to see a better example.

Now in this slide the dragon on the left looks decent but it’s probably not what the artist had envisioned as optimal. Apply Tessellation and displacement mapping and you get the dragon on the right which looks more like what we envision a dragon should look like. The house on the right the roof looks flat and is nothing more than a painted on skin, apply tessellation and you get raised roof tiles. Small changes that make a big difference to the eye.

Here’s the block diagram of Tessellation in DX11. The data flows from the Vertex to the patch assembly then to the Hull where the Tesselator takes over if needed. At that point processing becomes parallel and remains parallel through the rest of the workflow. If Tessellation isn’t required the Tesselator is bypassed and data moves on to the Domain and on to the Primitive assembly and finally on to the Geometry engine. The diagram is a little deceptive because it downplays one of Fermi’s evolutionary leaps, parallel triangle production.
All of that talk about Tessellation is fine and good but check out the Tessellation Water Demo we linked in and you can see the real benefit of Tessellation. Keep in mind that it’s scalable to the amount of processing power you have, Once you’ve seen the video we think that you will understand why Tessellation and FERMI being designed for the growth of Tessellation in the game development industry is so important. You might also want to keep in mind wire frames and those tons and tons of triangles Fermi is so good at producing.

Now here’s the rough of it. Adding Tessellation to GT200 core GPU’s you get a bottleneck.GT200 had single triangle capabilities like all previous GPU’s (Nvidia and ATI and despite ATI’s loose word play about producing two triangles on 5xxx GPU’s in reality they just improved serial triangle production so if you fell for the 5xxx dual triangle production ATI hinted at we are here to tell you it’s still serial (single) triangle production).
Fermi got a shared L2 cache (768KB configurable) that drastically decreases the off die transport of data.
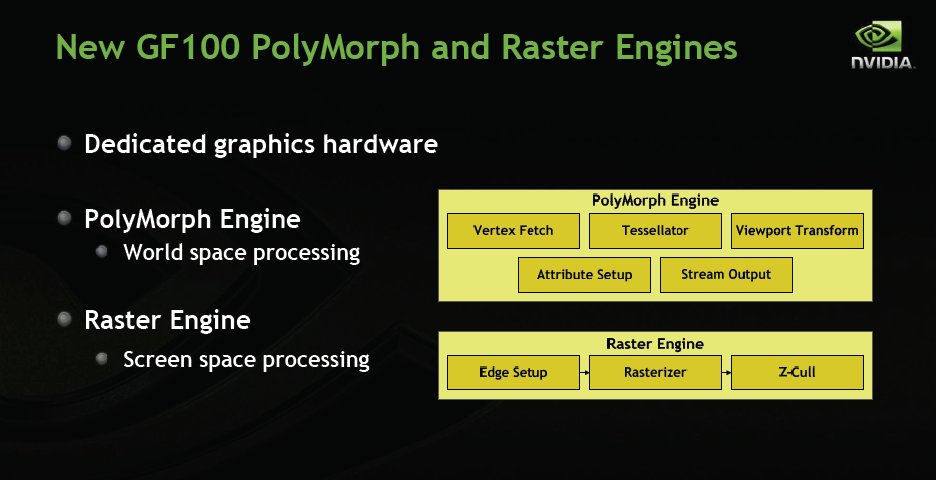
Fermi also gets a redesigned PolyMorph and Raster Engine setup.
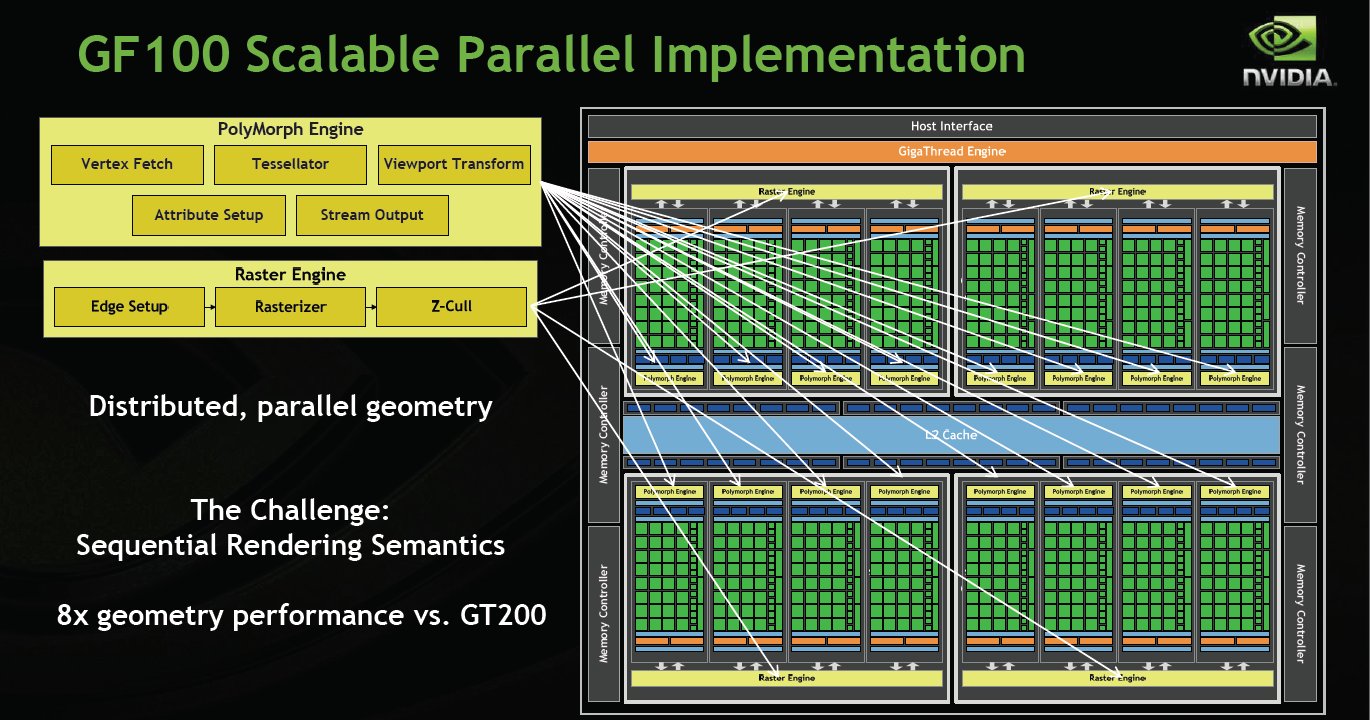
Here’s what we have been hammering all along Distributed Parallel geometry processing. Fermi sports 8x the geometry performance of GT200.
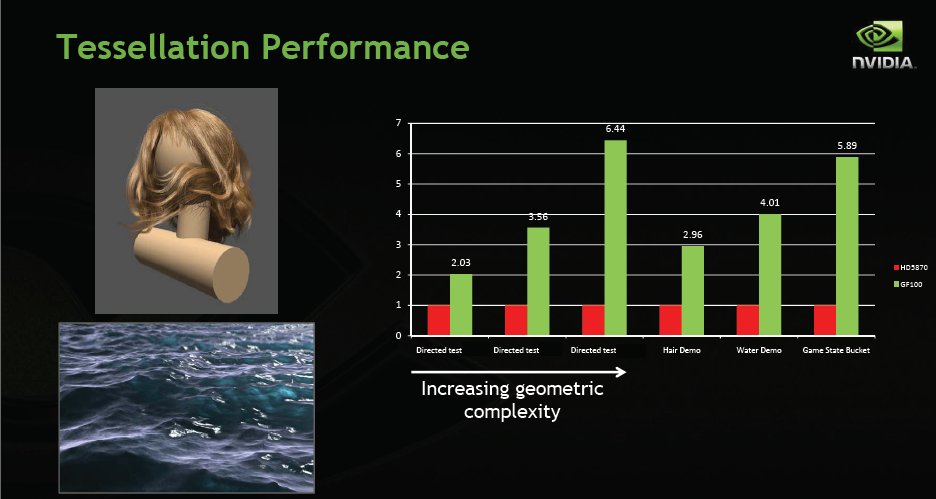
We saw the hair demo earlier and the Water demo is a little closer in the memory. THe red bars are using ATI 5870 performance as 100% the green bars are Fermi GF100 (full blown top end Fermi) and you can clearly see that in Tessellation in these examples is light years ahead of the 5xxx lineup. It follows that since so much of game development is in fact geometric programming (wireframes/triangles and now tessellation) that Fermi is going to be a monster GPU capable of producing an end user experience like nothing we have ever seen.
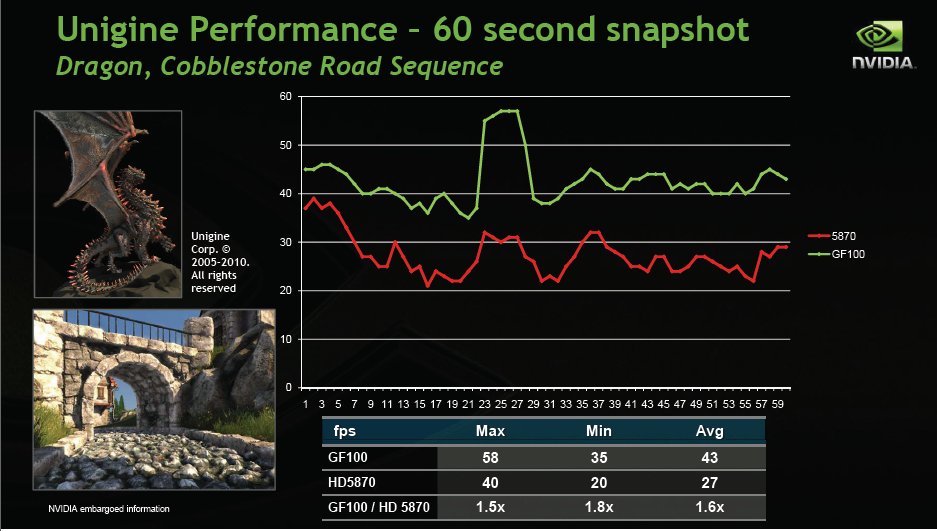
In Unigines bench using a 60 second snapshot Fermi’s performance ranged from 1.5x to 1.8x the performance of the 5870. Results will vary and shader and geometry heavy games will show Fermi’s true power.

Geometry shader performance on Fermi is off the map. Again using ATI 5870 for a reference as 100% Fermi is topping that by a factor of 4 – 4.7x.
Fermi for Gaming
As we all know Nvidia’s bread and butter is gaming and not just gaming but improving and driving the cutting edge of gaming. The Nvidia philosophy of delivering the best possible end user experience drives their concepts and designs for their GPU’s. With that kind of commitment it’s no surprise that Fermi is a laser precise answer to today’s gaming needs and it’s design is meant to carry GPU design and gaming into to future.

As usual the first slide from the deck is just introducing the topic.

Fermi brings a lot to the table and it features new caching and a shared configurable L2 cache, concurrent kernels, context switching, and fast atomics. It also has support for C++ and Visual studio integration.

A lot of people when they think of Cuda think folding but it’s more than just that. Nvidia has expanded support to C++ and still supports C, OpenCL, Direct Compute, proprietary PhysX and OptiX Ray Tracing.

Gaming specifically we get histograms, convolutions, depth of field, and motion blurs as well as static blurs. People think blur why would we want blurs. That’s the way the human eye works, we focus on one point or area and anything beyond that point blurs. Motion wise if something moves to fast our eyes can’t see it but he brain fills in the gaps and we see a blur.
For simulations Fermi brings Physics animation and AI. Physics (PhysX) brings more realism through increased destruction of in game materials and realism through accurate calculation of how things will act. AI has been an issue for a while, put to much AI into a game and things bog down. Fermi can help relieve that problem and allow for more in game AI’s to dispatch.
Fermi also offers Hybrid Rendering in the form of Order-independent transparency (OIT), Alias-Free Shadow Maps, Ray Tracing, and Voxel rendering.

What does a lot of that add up to. A sharp image in the foreground blending seamlessly to a blurred background. (Including but not limited to)

AI path finding, surely if you game you’ve seen enemy AI bouncing off obstructions in their path. It happens and we just get used to it and off the AI that’s stuck during path finding. Fermi has 3x the AI path finding capabilities of GT200 so now it’s just up to the game developers to learn better AI techniques to take advantage of that.

Accelerated Jitter sampling. Layman’s terms pixel pattern changing to blend in game materiel to a more pleasing (to the eye) image.

Fluid, smoke, water, shadows, and dust have always been a serious impediment in game realism. Water in general is often just a shifting shaded skin that alternates to fool the eye a little. PhysX enables the shifting of the simulation required for the computations from the CPU to the GPU and Fermi is almost twice as fast as GT200. More PhysX more realism less that doesn’t look quite right. Less that doesn’t look quite right means more realism.
PhysX is hard to explain but seeing is believing. Here’s a YouTube of a PhysX SPH Fluid Simulation. One YouTube is worth a thousand words.

Ray Tracing and it’s persistence forces it’s inclusion in game developing. Ray tracing depending on the length of the trace (say infinity) can be very demanding so it’s used sparingly. Fermi will allow for more use of ray tracing and is up to 4x faster than GT200.
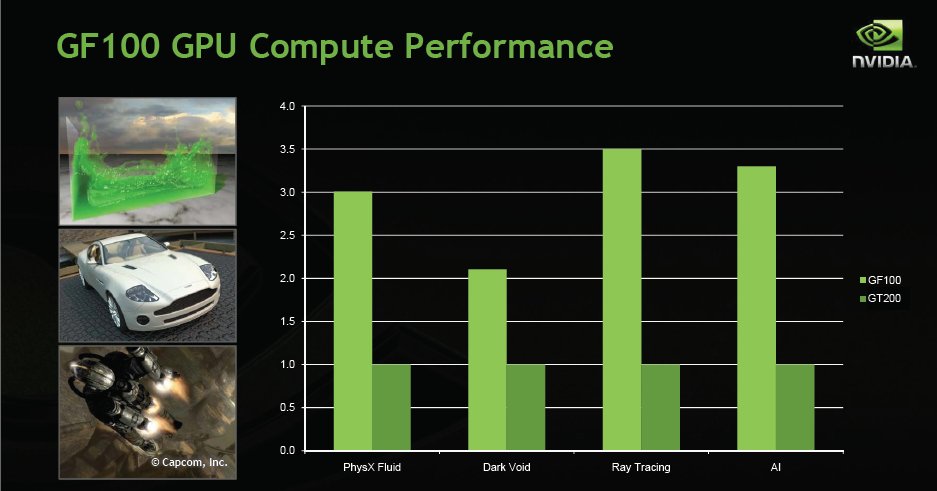
Fermi’s GPU compute performance ranges from slightly over 2x the performance of GT200 to 3.5x the performance in these tests.

This slide pretty much speaks for itself, notice the up to 2x performance over GTX-200.
Rocket Sled Demo
Nvidia gave us a peek at a new demo they are shipping with Fermi called the “Rocket Sled Demo”. We’ll have a YouTube of it later in the section but without PhysX and 3D Vision you won’t get the full jaw dropping experience.

The usual introductory slide.

The Supersonic Sled demo is designed to show Fermi’s power and feature set and we have to tell you it’s more than we expected.

Like we all know each little addition of eye candy leads to a conglomerate more realistic game.

Nvidia wanted a fun demo designed to explode, ready to blow off the track, and some guy is strapped in.

They started with a few concepts for the sled and drew from a few real life shots of existing sleds.

They took what they had learned and extrapolated it to the look they felt right for the demo.

From the initial rough beginnings they morfed it into what they wanted.

They they threw a little Nvidia magic at it to make it special.
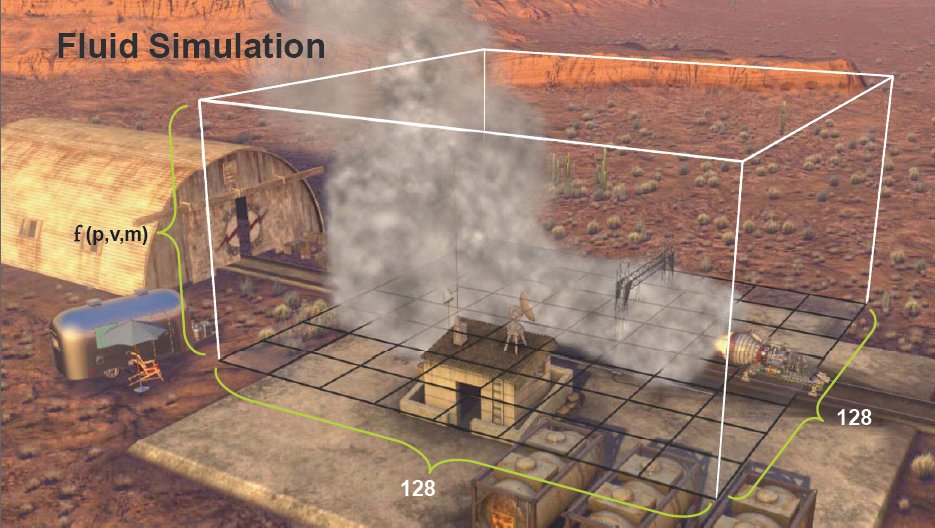
They tossed in some fluid (smoke) simulation to pop the eye.

Then they tossed in dust, explosions, and smoke trails from failed components.
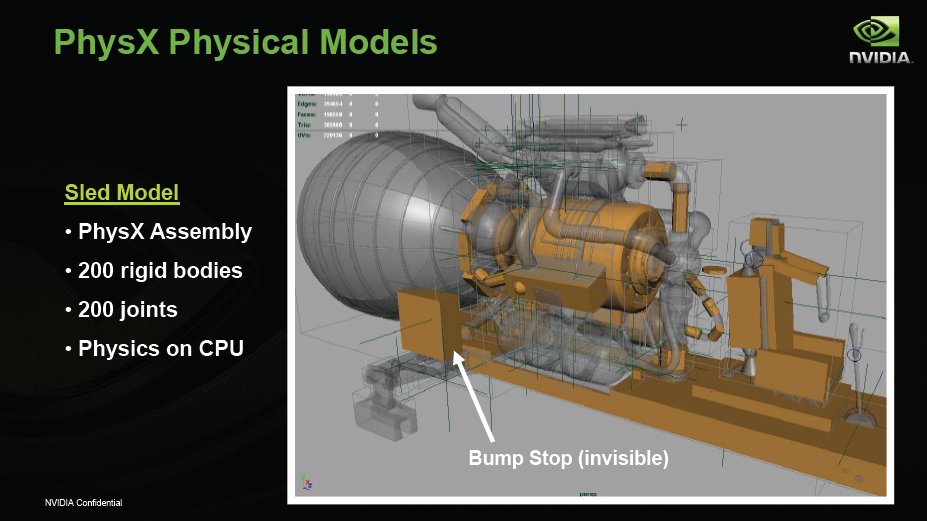
Once they put the Nvidia spin on it they defined the PhysX attributes.

Here’s how the CPU to GPU handshake (communications) are handled.

They wanted an animated face for the pilot and chose a beloved character (Barney Fife from Mayberry RFD) to use as a mdel for the pilot.

They modeled the pilots body on PhysX and defined the PhysX zone. Notice they shifted to more cartoon like because they felt that to realistic might get a little gory for general public consumption.
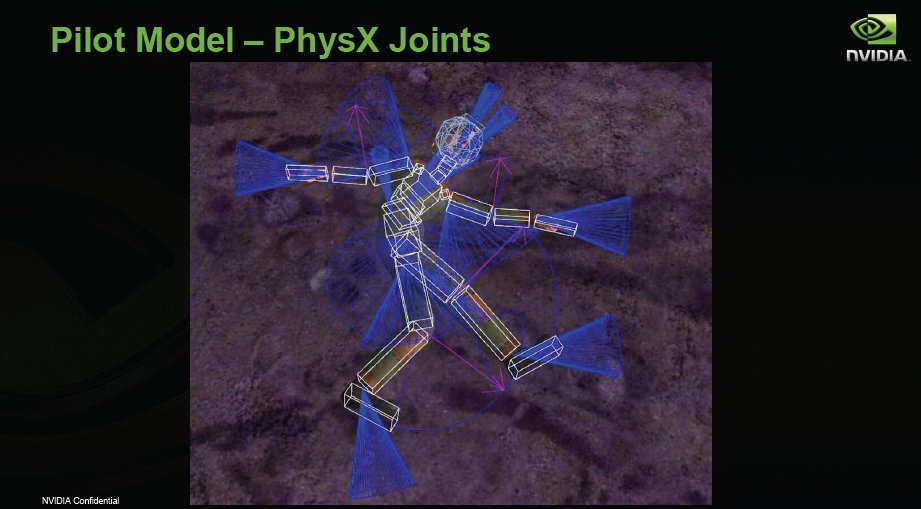
Then they defined the pilot’s joints with their PhysX engine (using APEX).
Rocket Sled Demo

Thye, of course, needed to test the pilots joints and the PhysX assigned to them and it’s looking pretty good here.

SO how do they handle the pilots face with the myrads of changes forced on it from G-Forces?

They decided to define the facial features like cloth (PhysX APEX supported) so they could give the poor guys face a good workout.

Then they needed an environment for the sled to run in so they did a concept drawing.

Then they wireframed and tessellated it giving it a desert look and feel like something out of one of the first color westerns.

Then here they have the sled in the environment they created and needed a few things to blow up as the sled runs past.

They built a bridge and a few other things into the demo so they could destroy them. Large chunks we have 1500, and small chunks we have 40,000.

How far did they crank it up, we saw a million particles acting much like water.

Hard to believe there’s one million articles floating around without the entire rig slowing to a crawel.

The needed some desert backdrop so they wireframed and tessellated it

Just imagin how many triangles the GPU has to spit out for this one terrain feature.

Once they had the terrain right they needed to shade it so it looks good to the eye.
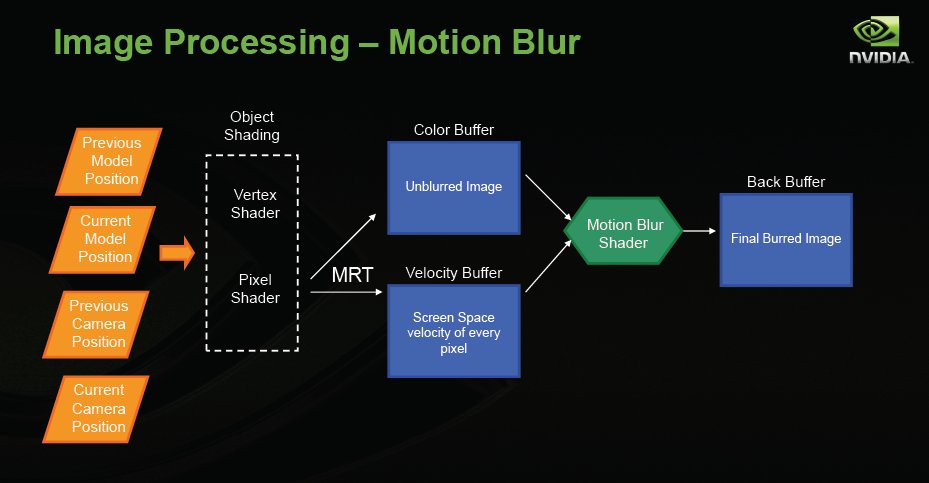
Moving at supersonic speeds things are going to blur and here’s how that’s handled.

Here’s a little of the blur, don’t worry it all comes together in the YouTube.

They tossed in a lot of Fermi’s new features and made it PhysX and 3D drooltastic.
Here’s what you’ve been waiting on, it’s in 720p so it might take a minute to fully load. It’s from the floor of CES so you might want to mute sound.
Conclusion
Fermi’s release is scheduled for the end of Q1 2010 but the core is in it’s productions stage. In our 7 hour meeting with Nvidia we saw and experienced a lot of Fermi and from the enthusiasm dripping from the Nvidia people you can tell Fermi is going to rock the graphics world. Just how rocking we’ll have to wait and see because while we saw a few benchmarks on Fermi it wasn’t a final product and the drivers for it haven’t been finalized so rather than release rough benches we would prefer to wait until we have a refrence GPU in hand and bench it ourselves.
We talked a lot about Fermi but some things were Tabu, like core clocks, memory clocks, performance numbers and specific release date.
It was a little bit of a paper launch but we’d rather have information direct from the Nvidia crew than speculation from 3rd party sources. It might have been paper but it was pretty paper.
We can’t wait for hands on Fermi and left Vegas with the feeling that this is one of those products that can and will change the face of gaming in a lasting manner.
We’d like to thank the Nvidia crew for all the time they spent with us during and after the meeting. The meeting was great and after the meeting, well what happens in Vegas stays in Vegas.



